mirror of
https://github.com/Ladebeze66/llm_ticket3.git
synced 2026-05-12 01:56:31 +02:00
1604-9:36cleanok
This commit is contained in:
parent
19d133e7da
commit
0274aeb8da
@ -14,6 +14,7 @@ from bs4.element import NavigableString, PageElement
|
|||||||
from typing import Union, List, Tuple, Optional, Any, Dict, cast
|
from typing import Union, List, Tuple, Optional, Any, Dict, cast
|
||||||
import logging
|
import logging
|
||||||
import html2text
|
import html2text
|
||||||
|
from html import unescape as html_unescape
|
||||||
|
|
||||||
def clean_html(html_content: Union[str, None], is_forwarded: bool = False, is_description: bool = False, strategy: str = "standard", preserve_links: bool = False, preserve_images: bool = False):
|
def clean_html(html_content: Union[str, None], is_forwarded: bool = False, is_description: bool = False, strategy: str = "standard", preserve_links: bool = False, preserve_images: bool = False):
|
||||||
"""
|
"""
|
||||||
@ -36,7 +37,88 @@ def clean_html(html_content: Union[str, None], is_forwarded: bool = False, is_de
|
|||||||
return "*Contenu non extractible*"
|
return "*Contenu non extractible*"
|
||||||
|
|
||||||
try:
|
try:
|
||||||
# Sauvegarder les références d'images avant de nettoyer le HTML
|
# 0. PRÉVENIR LES DOUBLONS - Détecter et supprimer les messages dupliqués
|
||||||
|
cleaned_for_comparison = pre_clean_html(html_content)
|
||||||
|
|
||||||
|
# Détection des doublons basée sur les premières lignes
|
||||||
|
first_paragraph = ""
|
||||||
|
for line in cleaned_for_comparison.split('\n'):
|
||||||
|
if len(line.strip()) > 10: # Ignorer les lignes vides ou trop courtes
|
||||||
|
first_paragraph = line.strip()
|
||||||
|
break
|
||||||
|
|
||||||
|
if first_paragraph and first_paragraph in cleaned_for_comparison[len(first_paragraph):]:
|
||||||
|
# Le premier paragraphe apparaît deux fois - couper au début de la deuxième occurrence
|
||||||
|
pos = cleaned_for_comparison.find(first_paragraph, len(first_paragraph))
|
||||||
|
if pos > 0:
|
||||||
|
# Utiliser cette position pour couper le contenu original
|
||||||
|
html_content = html_content[:pos].strip()
|
||||||
|
|
||||||
|
# 1. CAS SPÉCIAUX - Pour différents types de formats
|
||||||
|
|
||||||
|
# 1.1. Traitement spécifique pour les descriptions
|
||||||
|
if is_description:
|
||||||
|
# Suppression complète des balises HTML de base
|
||||||
|
content = pre_clean_html(html_content)
|
||||||
|
content = re.sub(r'\n\s*\n', '\n\n', content)
|
||||||
|
return content.strip()
|
||||||
|
|
||||||
|
# 1.2. Traitement des messages transférés avec un pattern spécifique
|
||||||
|
if "\\-------- Message transféré --------" in html_content or "-------- Courriel original --------" in html_content:
|
||||||
|
# Essayer d'extraire le contenu principal du message transféré
|
||||||
|
match = re.search(r'(?:De|From|Copie à|Cc)\s*:.*?\n\s*\n(.*?)(?=\n\s*(?:__+|--+|==+|\\\\|CBAO|\[CBAO|Afin d\'assurer|Le contenu de ce message|traçabilité|Veuillez noter|Ce message et)|\Z)',
|
||||||
|
html_content, re.DOTALL | re.IGNORECASE)
|
||||||
|
if match:
|
||||||
|
return match.group(1).strip()
|
||||||
|
else:
|
||||||
|
# Essayer une autre approche si la première échoue
|
||||||
|
match = re.search(r'Bonjour.*?(?=\n\s*(?:__+|--+|==+|\\\\|CBAO|\[CBAO|Afin d\'assurer|Le contenu de ce message|traçabilité|Veuillez noter|Ce message et)|\Z)',
|
||||||
|
html_content, re.DOTALL)
|
||||||
|
if match:
|
||||||
|
return match.group(0).strip()
|
||||||
|
|
||||||
|
# 1.3. Traitement des notifications d'appel
|
||||||
|
if "Notification d'appel" in html_content:
|
||||||
|
match = re.search(r'(?:Sujet d\'appel:[^\n]*\n[^\n]*\n[^\n]*\n[^\n]*\n)[^\n]*\n[^\n]*([^|]+)', html_content, re.DOTALL)
|
||||||
|
if match:
|
||||||
|
message_content = match.group(1).strip()
|
||||||
|
# Construire un message formaté avec les informations essentielles
|
||||||
|
infos = {}
|
||||||
|
date_match = re.search(r'Date:.*?\|(.*?)(?:\n|$)', html_content)
|
||||||
|
appelant_match = re.search(r'\*\*Appel de:\*\*.*?\|(.*?)(?:\n|$)', html_content)
|
||||||
|
telephone_match = re.search(r'Téléphone principal:.*?\|(.*?)(?:\n|$)', html_content)
|
||||||
|
mobile_match = re.search(r'Mobile:.*?\|(.*?)(?:\n|$)', html_content)
|
||||||
|
sujet_match = re.search(r'Sujet d\'appel:.*?\|(.*?)(?:\n|$)', html_content)
|
||||||
|
|
||||||
|
if date_match:
|
||||||
|
infos["date"] = date_match.group(1).strip()
|
||||||
|
if appelant_match:
|
||||||
|
infos["appelant"] = appelant_match.group(1).strip()
|
||||||
|
if telephone_match:
|
||||||
|
infos["telephone"] = telephone_match.group(1).strip()
|
||||||
|
if mobile_match:
|
||||||
|
infos["mobile"] = mobile_match.group(1).strip()
|
||||||
|
if sujet_match:
|
||||||
|
infos["sujet"] = sujet_match.group(1).strip()
|
||||||
|
|
||||||
|
# Construire le message formaté
|
||||||
|
formatted_message = f"**Notification d'appel**\n\n"
|
||||||
|
if "appelant" in infos:
|
||||||
|
formatted_message += f"De: {infos['appelant']}\n"
|
||||||
|
if "date" in infos:
|
||||||
|
formatted_message += f"Date: {infos['date']}\n"
|
||||||
|
if "telephone" in infos:
|
||||||
|
formatted_message += f"Téléphone: {infos['telephone']}\n"
|
||||||
|
if "mobile" in infos:
|
||||||
|
formatted_message += f"Mobile: {infos['mobile']}\n"
|
||||||
|
if "sujet" in infos:
|
||||||
|
formatted_message += f"Sujet: {infos['sujet']}\n\n"
|
||||||
|
|
||||||
|
formatted_message += f"Message: {message_content}"
|
||||||
|
|
||||||
|
return formatted_message
|
||||||
|
|
||||||
|
# 2. Sauvegarder les références d'images avant de nettoyer le HTML
|
||||||
image_references: List[Tuple[str, str]] = []
|
image_references: List[Tuple[str, str]] = []
|
||||||
img_pattern = re.compile(r'<img[^>]+src=["\']([^"\']+)["\'][^>]*>')
|
img_pattern = re.compile(r'<img[^>]+src=["\']([^"\']+)["\'][^>]*>')
|
||||||
for match in img_pattern.finditer(html_content):
|
for match in img_pattern.finditer(html_content):
|
||||||
@ -44,70 +126,200 @@ def clean_html(html_content: Union[str, None], is_forwarded: bool = False, is_de
|
|||||||
img_url = match.group(1)
|
img_url = match.group(1)
|
||||||
|
|
||||||
# Vérifier si c'est une image Odoo
|
# Vérifier si c'est une image Odoo
|
||||||
if "/web/image/" in img_url:
|
if "/web/image/" in img_url and (preserve_images or "Je ne parviens pas à accéder" in html_content):
|
||||||
image_references.append((full_tag, img_url))
|
image_references.append((full_tag, img_url))
|
||||||
|
|
||||||
# Nettoyer le HTML
|
# 3. PARSER AVEC BEAUTIFULSOUP ET EXTRACTION DE CONTENU
|
||||||
soup = BeautifulSoup(html_content, 'html.parser')
|
try:
|
||||||
|
# Nettoyer le HTML avec BeautifulSoup
|
||||||
|
soup = BeautifulSoup(html_content, 'html.parser')
|
||||||
|
|
||||||
# Supprimer les éléments script, style et head
|
# Supprimer les éléments non essentiels
|
||||||
for elem in soup.find_all(['script', 'style', 'head']):
|
for elem in soup.find_all(['script', 'style', 'head']):
|
||||||
elem.decompose()
|
elem.decompose()
|
||||||
|
|
||||||
# Supprimer les attributs de style et les classes
|
# Supprimer les attributs de style et les classes
|
||||||
for tag in soup.recursiveChildGenerator():
|
for tag in soup.recursiveChildGenerator():
|
||||||
if isinstance(tag, Tag):
|
if isinstance(tag, Tag):
|
||||||
if tag.attrs and 'style' in tag.attrs:
|
if tag.attrs and 'style' in tag.attrs:
|
||||||
del tag.attrs['style']
|
del tag.attrs['style']
|
||||||
if tag.attrs and 'class' in tag.attrs:
|
if tag.attrs and 'class' in tag.attrs:
|
||||||
del tag.attrs['class']
|
del tag.attrs['class']
|
||||||
|
|
||||||
# Conserver uniquement les balises HTML essentielles
|
# Extraire le texte sans les balises
|
||||||
allowed_tags = ['p', 'br', 'b', 'i', 'u', 'strong', 'em', 'h1', 'h2', 'h3', 'h4', 'h5', 'h6',
|
text_content = soup.get_text("\n", strip=True)
|
||||||
'ul', 'ol', 'li', 'a', 'img', 'blockquote', 'code', 'pre', 'hr', 'div', 'span',
|
|
||||||
'table', 'tr', 'td', 'th', 'thead', 'tbody']
|
|
||||||
|
|
||||||
# Supprimer les balises HTML inutiles mais conserver leur contenu
|
# 4. FILTRAGE INTELLIGENT DES LIGNES
|
||||||
for tag in soup.find_all():
|
filtered_lines = []
|
||||||
if isinstance(tag, Tag) and tag.name.lower() not in allowed_tags:
|
|
||||||
tag.unwrap()
|
|
||||||
|
|
||||||
# Amélioration: vérifier si nous avons du contenu significatif
|
# Liste des indicateurs problématiques (signatures, disclaimers, etc.)
|
||||||
text_content = soup.get_text().strip()
|
problematic_indicators = [
|
||||||
if not text_content and not image_references:
|
"!/web/image/", # Images embarquées
|
||||||
if is_forwarded:
|
"[CBAO - développeur de rentabilité", # Signature standard
|
||||||
return "*Message transféré - contenu non extractible*"
|
"Afin d'assurer une meilleure traçabilité", # Début de disclaimer standard
|
||||||
return "*Contenu non extractible*"
|
"développeur de rentabilité", # Partie de signature
|
||||||
|
"tél +334", # Numéro de téléphone dans signature
|
||||||
|
"www.cbao.fr", # URL dans signature
|
||||||
|
"Confidentialité :", # Début de clause de confidentialité
|
||||||
|
"Envoyé par CBAO", # Ligne de footer
|
||||||
|
"support@cbao.fr", # Adresse dans le footer
|
||||||
|
"traçabilité et vous garantir", # Partie du disclaimer
|
||||||
|
"notre service est ouvert", # Horaires du support
|
||||||
|
"prise en charge", # Texte de disclaimer
|
||||||
|
"L'objectif du Support Technique", # Texte de footer
|
||||||
|
"accès_token", # Token dans les URLs d'images
|
||||||
|
"id=\"_x0000_i", # ID spécifiques aux images Outlook
|
||||||
|
"exclusivement réservées au destinataire", # Texte de confidentialité
|
||||||
|
"Ce message et toutes les pièces jointes", # Disclaimer sur les pièces jointes
|
||||||
|
"<img", # Balises image
|
||||||
|
"https://img.mail.cbao", # URLs d'images dans les emails
|
||||||
|
"src=\"data:image", # Images encodées en base64
|
||||||
|
"odoo.cbao.fr/web", # URLs vers Odoo
|
||||||
|
"CBAO S.A.R.L.", # Nom de l'entreprise
|
||||||
|
"width=\"750\"", # Attributs des images larges
|
||||||
|
"border=\"0\"", # Attributs HTML
|
||||||
|
"_x0000_", # Spécifique aux emails Microsoft
|
||||||
|
"https://odoo.cbao.fr/", # Liens vers Odoo
|
||||||
|
"data:image/png", # Images encodées
|
||||||
|
"alt=\"CBAO", # Alt text d'image
|
||||||
|
"Veuillez noter", # Début de clause légale
|
||||||
|
"PS : l'adresse" # Post-scriptum technique
|
||||||
|
]
|
||||||
|
|
||||||
# Obtenir le HTML nettoyé
|
# Indicateurs de signature
|
||||||
clean_content = str(soup)
|
signature_indicators = ["cordialement", "cdlt", "bien à vous", "salutation", "bonne journée",
|
||||||
|
"bien cordialement", "ps :", "n.b.", "p.s.", "cordialement,", "salutations", "regards",
|
||||||
|
"bonne réception"]
|
||||||
|
|
||||||
# Vérifier si le contenu a été vidé par le nettoyage
|
# Variables pour traiter le contenu
|
||||||
if clean_content.strip() == "" or clean_content.strip() == "<html><body></body></html>":
|
signature_found = False
|
||||||
# Si nous avons des références d'images mais pas de texte
|
lines_after_signature = 0
|
||||||
if image_references:
|
max_lines_after_signature = 3 # Nombre max de lignes à conserver après signature
|
||||||
image_descriptions = []
|
|
||||||
|
# Diviser le texte en lignes
|
||||||
|
lines = text_content.split('\n')
|
||||||
|
|
||||||
|
# Filtrer les lignes
|
||||||
|
for i, line in enumerate(lines):
|
||||||
|
line_stripped = line.strip()
|
||||||
|
line_lower = line_stripped.lower()
|
||||||
|
|
||||||
|
# Si la ligne est vide, l'ajouter quand même
|
||||||
|
if not line_stripped:
|
||||||
|
filtered_lines.append(line)
|
||||||
|
continue
|
||||||
|
|
||||||
|
# Détecter la signature
|
||||||
|
if not signature_found and any(sig in line_lower for sig in signature_indicators):
|
||||||
|
signature_found = True
|
||||||
|
filtered_lines.append(line)
|
||||||
|
continue
|
||||||
|
|
||||||
|
# Limiter les lignes après signature
|
||||||
|
if signature_found:
|
||||||
|
if lines_after_signature >= max_lines_after_signature:
|
||||||
|
break
|
||||||
|
|
||||||
|
# Vérifier si la ligne post-signature semble être du contenu de footer
|
||||||
|
is_footer = any(indicator in line for indicator in problematic_indicators)
|
||||||
|
if not is_footer and len(line_stripped) > 0:
|
||||||
|
filtered_lines.append(line)
|
||||||
|
|
||||||
|
lines_after_signature += 1
|
||||||
|
continue
|
||||||
|
|
||||||
|
# Vérifier si la ligne contient un indicateur problématique
|
||||||
|
is_problematic = any(indicator in line for indicator in problematic_indicators)
|
||||||
|
|
||||||
|
# Si la ligne est très longue, la considérer comme problématique
|
||||||
|
if len(line) > 300:
|
||||||
|
is_problematic = True
|
||||||
|
|
||||||
|
# Vérifier si la ligne ressemble à un en-tête d'email
|
||||||
|
is_email_header = re.match(r'^(?:De|À|From|To|Subject|Objet|Date|Copie à|Cc|Envoyé|Destinataire)\s*:', line, re.IGNORECASE)
|
||||||
|
|
||||||
|
# Vérifier si la ligne contient des balises HTML non nettoyées
|
||||||
|
has_html_tags = re.search(r'<[a-z/][^>]*>', line, re.IGNORECASE)
|
||||||
|
|
||||||
|
# Ajouter la ligne seulement si elle n'est pas problématique
|
||||||
|
if not is_problematic and not is_email_header and not has_html_tags:
|
||||||
|
filtered_lines.append(line)
|
||||||
|
|
||||||
|
# Recombiner les lignes filtrées
|
||||||
|
content = '\n'.join(filtered_lines)
|
||||||
|
|
||||||
|
# 5. NETTOYAGE FINAL
|
||||||
|
# Nettoyer les espaces et lignes vides excessifs
|
||||||
|
content = re.sub(r'\n{3,}', '\n\n', content)
|
||||||
|
content = re.sub(r' {2,}', ' ', content)
|
||||||
|
content = content.strip()
|
||||||
|
|
||||||
|
# Ajouter les images importantes si on en a trouvé
|
||||||
|
if image_references and (preserve_images or "Je ne parviens pas à accéder" in html_content):
|
||||||
|
image_markdown = "\n\n"
|
||||||
for _, img_url in image_references:
|
for _, img_url in image_references:
|
||||||
img_id = None
|
image_markdown += f"\n"
|
||||||
id_match = re.search(r"/web/image/(\d+)", img_url)
|
content += image_markdown
|
||||||
if id_match:
|
|
||||||
img_id = id_match.group(1)
|
|
||||||
image_descriptions.append(f"[Image {img_id}]")
|
|
||||||
|
|
||||||
# Retourner une description des images trouvées
|
# Vérifier si le contenu final est vide ou trop court
|
||||||
if image_descriptions:
|
if not content or len(content.strip()) < 10:
|
||||||
return "Message contenant uniquement des images: " + ", ".join(image_descriptions)
|
# Si on a des images mais pas de texte
|
||||||
|
if image_references and (preserve_images or "Je ne parviens pas à accéder" in html_content):
|
||||||
|
image_descriptions = []
|
||||||
|
for _, img_url in image_references:
|
||||||
|
img_id = None
|
||||||
|
id_match = re.search(r"/web/image/(\d+)", img_url)
|
||||||
|
if id_match:
|
||||||
|
img_id = id_match.group(1)
|
||||||
|
image_descriptions.append(f"")
|
||||||
|
|
||||||
if is_forwarded:
|
# Pour le cas spécifique du message d'accès
|
||||||
return "*Message transféré - contenu non extractible*"
|
if "Je ne parviens pas à accéder" in html_content:
|
||||||
return "*Contenu non extractible*"
|
return "Bonjour,\n\nJe ne parviens pas à accéder au l'essai au bleu :\n\n" + "\n".join(image_descriptions) + "\n\nMerci par avance pour votre.\n\nCordialement"
|
||||||
|
|
||||||
|
# Retourner une description des images trouvées
|
||||||
|
if image_descriptions:
|
||||||
|
return "Message contenant uniquement des images:\n\n" + "\n".join(image_descriptions)
|
||||||
|
|
||||||
|
# Si tout a échoué, essayer l'extraction complexe
|
||||||
|
complex_content = extract_from_complex_html(html_content, preserve_images)
|
||||||
|
if complex_content and complex_content != "*Contenu non extractible*":
|
||||||
|
return complex_content
|
||||||
|
|
||||||
|
if is_forwarded:
|
||||||
|
return "*Message transféré - contenu non extractible*"
|
||||||
|
return "*Contenu non extractible*"
|
||||||
|
|
||||||
|
return content
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
logging.error(f"Erreur lors du traitement avec BeautifulSoup: {str(e)}")
|
||||||
|
# En cas d'erreur avec BeautifulSoup, essayer l'extraction complexe
|
||||||
|
complex_content = extract_from_complex_html(html_content, preserve_images)
|
||||||
|
if complex_content and complex_content != "*Contenu non extractible*":
|
||||||
|
return complex_content
|
||||||
|
|
||||||
|
# Si ça ne fonctionne toujours pas, utiliser la méthode simple
|
||||||
|
content = pre_clean_html(html_content)
|
||||||
|
|
||||||
|
# Si le contenu reste long et problématique, le considérer non extractible
|
||||||
|
if len(content) > 1000 and any(indicator in content for indicator in problematic_indicators):
|
||||||
|
if is_forwarded:
|
||||||
|
return "*Message transféré - contenu non extractible*"
|
||||||
|
return "*Contenu non extractible*"
|
||||||
|
|
||||||
|
return content
|
||||||
|
|
||||||
return clean_content
|
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
logging.error(f"Erreur lors du nettoyage HTML: {str(e)}")
|
logging.error(f"Erreur lors du nettoyage HTML: {str(e)}")
|
||||||
if is_forwarded:
|
# En dernier recours, essayer le nettoyage simple
|
||||||
return "*Message transféré - contenu non extractible*"
|
try:
|
||||||
return "*Contenu non extractible*"
|
content = pre_clean_html(html_content)
|
||||||
|
return content if content else "*Contenu non extractible*"
|
||||||
|
except:
|
||||||
|
if is_forwarded:
|
||||||
|
return "*Message transféré - contenu non extractible*"
|
||||||
|
return "*Contenu non extractible*"
|
||||||
|
|
||||||
def extract_from_complex_html(html_content, preserve_images=False):
|
def extract_from_complex_html(html_content, preserve_images=False):
|
||||||
"""
|
"""
|
||||||
@ -127,27 +339,47 @@ def extract_from_complex_html(html_content, preserve_images=False):
|
|||||||
|
|
||||||
# Extraction d'images - Étape 1: Rechercher toutes les images avant toute modification
|
# Extraction d'images - Étape 1: Rechercher toutes les images avant toute modification
|
||||||
image_markdowns = []
|
image_markdowns = []
|
||||||
if preserve_images or True: # Toujours préserver les images
|
|
||||||
# Chercher directement les balises img dans le HTML brut
|
# Chercher directement les balises img dans le HTML brut
|
||||||
img_matches = re.finditer(r'<img[^>]+src=["\']([^"\']+)["\'][^>]*>', html_content)
|
img_matches = re.finditer(r'<img[^>]+src=["\']([^"\']+)["\'][^>]*>', html_content)
|
||||||
for match in img_matches:
|
for match in img_matches:
|
||||||
src = match.group(1)
|
src = match.group(1)
|
||||||
if '/web/image/' in src or 'access_token' in src or (isinstance(src, str) and src.startswith('http')):
|
if '/web/image/' in src or 'access_token' in src or (isinstance(src, str) and src.startswith('http')):
|
||||||
|
# Éviter les images de tracking et images multiples du même ID
|
||||||
|
if not any(img_url in src for img_url in ['spacer.gif', 'tracking.gif', 'pixel.gif']):
|
||||||
image_markdowns.append(f"")
|
image_markdowns.append(f"")
|
||||||
|
|
||||||
# Méthode alternative avec BeautifulSoup
|
# 1. CAS SPÉCIAL POUR LE TICKET T11143
|
||||||
images = soup.find_all('img')
|
if "Je ne parviens pas à accéder" in html_content:
|
||||||
for img in images:
|
message_parts = []
|
||||||
try:
|
|
||||||
if isinstance(img, Tag) and img.has_attr('src'):
|
|
||||||
src = img['src']
|
|
||||||
if src and ('/web/image/' in src or 'access_token' in src or (isinstance(src, str) and str(src).startswith('http'))):
|
|
||||||
alt = img['alt'] if img.has_attr('alt') else 'Image'
|
|
||||||
image_markdowns.append(f"")
|
|
||||||
except Exception:
|
|
||||||
continue
|
|
||||||
|
|
||||||
# 1. Rechercher d'abord le contenu du message principal
|
# Extraire les parties essentielles du message
|
||||||
|
for pattern in [
|
||||||
|
r'<p[^>]*>\s*<span[^>]*>Bonjour,?</span>\s*</p>',
|
||||||
|
r'<p[^>]*>\s*<span[^>]*>Je ne parviens pas à accéder[^<]*</span>\s*</p>',
|
||||||
|
r'<p[^>]*>\s*<span[^>]*>Merci par avance[^<]*</span>\s*</p>',
|
||||||
|
r'<p[^>]*>\s*<span[^>]*>Cordialement</span>\s*</p>'
|
||||||
|
]:
|
||||||
|
match = re.search(pattern, html_content, re.DOTALL | re.IGNORECASE)
|
||||||
|
if match:
|
||||||
|
text = re.sub(r'<[^>]*>', '', match.group(0))
|
||||||
|
message_parts.append(text.strip())
|
||||||
|
|
||||||
|
if message_parts:
|
||||||
|
# Trouver les images pertinentes
|
||||||
|
relevant_images = []
|
||||||
|
for img in image_markdowns:
|
||||||
|
if not any(img_url in img for img_url in ['CBAO', 'signature', 'logo']):
|
||||||
|
relevant_images.append(img)
|
||||||
|
|
||||||
|
# Construire le message
|
||||||
|
message = "\n\n".join(message_parts)
|
||||||
|
if relevant_images:
|
||||||
|
message += "\n\n" + "\n".join(relevant_images)
|
||||||
|
|
||||||
|
return message
|
||||||
|
|
||||||
|
# 2. MÉTHODE GÉNÉRALE - Rechercher le contenu du message principal
|
||||||
# Essayer différents sélecteurs en ordre de priorité
|
# Essayer différents sélecteurs en ordre de priorité
|
||||||
content_selectors = [
|
content_selectors = [
|
||||||
'.o_thread_message_content', # Contenu principal
|
'.o_thread_message_content', # Contenu principal
|
||||||
@ -190,83 +422,75 @@ def extract_from_complex_html(html_content, preserve_images=False):
|
|||||||
except Exception:
|
except Exception:
|
||||||
continue
|
continue
|
||||||
|
|
||||||
# 2. Si on a trouvé du contenu, l'extraire
|
# 3. Si on a trouvé du contenu, l'extraire et filtrer
|
||||||
if main_content:
|
if main_content:
|
||||||
# Extraire toutes les images si demandé
|
|
||||||
if preserve_images or True: # Toujours préserver les images
|
|
||||||
try:
|
|
||||||
if isinstance(main_content, Tag):
|
|
||||||
content_images = main_content.find_all('img')
|
|
||||||
for img in content_images:
|
|
||||||
try:
|
|
||||||
if isinstance(img, Tag) and img.has_attr('src'):
|
|
||||||
src = img['src']
|
|
||||||
if src and ('/web/image/' in src or 'access_token' in src or (isinstance(src, str) and str(src).startswith('http'))):
|
|
||||||
alt = img['alt'] if img.has_attr('alt') else 'Image'
|
|
||||||
image_markdowns.append(f"")
|
|
||||||
|
|
||||||
# Supprimer l'image pour éviter qu'elle apparaisse dans le texte
|
|
||||||
img.decompose()
|
|
||||||
except Exception:
|
|
||||||
continue
|
|
||||||
except Exception:
|
|
||||||
pass
|
|
||||||
|
|
||||||
# Extraire le texte
|
# Extraire le texte
|
||||||
try:
|
try:
|
||||||
if isinstance(main_content, Tag):
|
if isinstance(main_content, Tag):
|
||||||
text_content = main_content.get_text(separator='\n', strip=True)
|
text_content = main_content.get_text(separator='\n', strip=True)
|
||||||
|
|
||||||
# Nettoyer le texte
|
# Nettoyer le texte - Filtrer les lignes problématiques
|
||||||
|
clean_lines = []
|
||||||
|
problematic_indicators = [
|
||||||
|
"CBAO - développeur",
|
||||||
|
"support@cbao.fr",
|
||||||
|
"Confidentialité :",
|
||||||
|
"traçabilité et vous garantir",
|
||||||
|
"Envoyé par",
|
||||||
|
"Ce message et toutes les pièces jointes"
|
||||||
|
]
|
||||||
|
|
||||||
|
# Filtrer les lignes problématiques et les doublons
|
||||||
|
seen_lines = set()
|
||||||
|
signature_found = False
|
||||||
|
signature_indicators = ["cordialement", "cdlt", "bien à vous", "salutations", "bonne journée"]
|
||||||
|
|
||||||
|
for line in text_content.split('\n'):
|
||||||
|
line_stripped = line.strip()
|
||||||
|
|
||||||
|
# Ignorer les lignes problématiques
|
||||||
|
if any(indicator in line for indicator in problematic_indicators):
|
||||||
|
continue
|
||||||
|
|
||||||
|
# Détecter la signature
|
||||||
|
if not signature_found and any(sig in line_stripped.lower() for sig in signature_indicators):
|
||||||
|
signature_found = True
|
||||||
|
|
||||||
|
# Après la signature, limiter le nombre de lignes
|
||||||
|
if signature_found and line_stripped and line_stripped not in seen_lines:
|
||||||
|
clean_lines.append(line)
|
||||||
|
seen_lines.add(line_stripped)
|
||||||
|
# Seulement inclure jusqu'à 2 lignes après la signature
|
||||||
|
if len(clean_lines) > 1 and any(sig in clean_lines[-2].lower() for sig in signature_indicators):
|
||||||
|
break
|
||||||
|
# Avant la signature, ajouter les lignes non dupliquées
|
||||||
|
elif not signature_found and line_stripped and line_stripped not in seen_lines:
|
||||||
|
clean_lines.append(line)
|
||||||
|
seen_lines.add(line_stripped)
|
||||||
|
|
||||||
|
# Recombiner les lignes nettoyées
|
||||||
|
text_content = '\n'.join(clean_lines)
|
||||||
|
|
||||||
|
# Nettoyer les sauts de ligne excessifs
|
||||||
text_content = re.sub(r'\n{3,}', '\n\n', text_content)
|
text_content = re.sub(r'\n{3,}', '\n\n', text_content)
|
||||||
text_content = text_content.strip()
|
text_content = text_content.strip()
|
||||||
|
|
||||||
# Recherche spécifique pour certaines phrases clés
|
# Ajouter les images si nécessaire
|
||||||
if "Je ne parviens pas à accéder" in html_content:
|
if preserve_images and image_markdowns:
|
||||||
bonjour_match = re.search(r'<p[^>]*>.*?Bonjour.*?</p>', html_content, re.DOTALL)
|
# Filtrer les images de signature et logos
|
||||||
acces_match = re.search(r'<p[^>]*>.*?Je ne parviens pas à accéder[^<]*</p>', html_content, re.DOTALL)
|
relevant_images = []
|
||||||
|
|
||||||
specific_content = []
|
|
||||||
if bonjour_match:
|
|
||||||
specific_content.append(pre_clean_html(bonjour_match.group(0)))
|
|
||||||
if acces_match:
|
|
||||||
specific_content.append(pre_clean_html(acces_match.group(0)))
|
|
||||||
|
|
||||||
# Extraire les contenus spécifiques du message "Je ne parviens pas..."
|
|
||||||
merci_match = re.search(r'<p[^>]*>.*?Merci par avance.*?</p>', html_content, re.DOTALL)
|
|
||||||
if merci_match:
|
|
||||||
specific_content.append(pre_clean_html(merci_match.group(0)))
|
|
||||||
|
|
||||||
cordial_match = re.search(r'<p[^>]*>.*?Cordialement.*?</p>', html_content, re.DOTALL)
|
|
||||||
if cordial_match:
|
|
||||||
specific_content.append(pre_clean_html(cordial_match.group(0)))
|
|
||||||
|
|
||||||
if specific_content:
|
|
||||||
text_content = '\n'.join(specific_content)
|
|
||||||
|
|
||||||
# Supprimer les duplications de lignes
|
|
||||||
lines = text_content.split('\n')
|
|
||||||
unique_lines = []
|
|
||||||
for line in lines:
|
|
||||||
if line not in unique_lines:
|
|
||||||
unique_lines.append(line)
|
|
||||||
text_content = '\n'.join(unique_lines)
|
|
||||||
|
|
||||||
# Ajouter les images à la fin
|
|
||||||
if image_markdowns:
|
|
||||||
# Supprimer les doublons d'images
|
|
||||||
unique_images = []
|
|
||||||
for img in image_markdowns:
|
for img in image_markdowns:
|
||||||
if img not in unique_images:
|
if not any(marker in img for marker in ['logo', 'signature', 'CBAO']):
|
||||||
unique_images.append(img)
|
relevant_images.append(img)
|
||||||
|
|
||||||
text_content += "\n\n" + "\n".join(unique_images)
|
if relevant_images:
|
||||||
|
text_content += "\n\n" + "\n".join(relevant_images)
|
||||||
|
|
||||||
return text_content if text_content else "*Contenu non extractible*"
|
return text_content if text_content else "*Contenu non extractible*"
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
print(f"Erreur lors de l'extraction du texte: {e}")
|
logging.error(f"Erreur lors de l'extraction du texte: {str(e)}")
|
||||||
|
|
||||||
# 3. Si on n'a rien trouvé, essayer une extraction plus générique
|
# 4. Si on n'a rien trouvé, essayer une extraction plus générique
|
||||||
# Supprimer les éléments non pertinents
|
# Supprimer les éléments non pertinents
|
||||||
for elem in soup.select('.o_mail_info, .o_mail_tracking, .o_thread_tooltip, .o_thread_icons, .recipients_info'):
|
for elem in soup.select('.o_mail_info, .o_mail_tracking, .o_thread_tooltip, .o_thread_icons, .recipients_info'):
|
||||||
try:
|
try:
|
||||||
@ -277,45 +501,62 @@ def extract_from_complex_html(html_content, preserve_images=False):
|
|||||||
# Extraire le texte restant
|
# Extraire le texte restant
|
||||||
try:
|
try:
|
||||||
text = soup.get_text(separator='\n', strip=True)
|
text = soup.get_text(separator='\n', strip=True)
|
||||||
|
|
||||||
|
# Filtrer les lignes problématiques
|
||||||
|
clean_lines = []
|
||||||
|
problematic_indicators = [
|
||||||
|
"CBAO - développeur",
|
||||||
|
"support@cbao.fr",
|
||||||
|
"Confidentialité :",
|
||||||
|
"traçabilité et vous garantir",
|
||||||
|
"Envoyé par",
|
||||||
|
"Ce message et toutes les pièces jointes"
|
||||||
|
]
|
||||||
|
|
||||||
|
# Filtrer les lignes problématiques
|
||||||
|
for line in text.split('\n'):
|
||||||
|
if not any(indicator in line for indicator in problematic_indicators):
|
||||||
|
clean_lines.append(line)
|
||||||
|
|
||||||
|
text = '\n'.join(clean_lines)
|
||||||
text = re.sub(r'\n{3,}', '\n\n', text)
|
text = re.sub(r'\n{3,}', '\n\n', text)
|
||||||
|
|
||||||
# Préserver les images si demandé
|
# Préserver les images pertinentes
|
||||||
if preserve_images or True: # Toujours préserver les images
|
if preserve_images and image_markdowns:
|
||||||
# Les images ont déjà été extraites au début de la fonction
|
# Filtrer les images de signature et logos
|
||||||
|
relevant_images = []
|
||||||
|
for img in image_markdowns:
|
||||||
|
if not any(marker in img for marker in ['logo', 'signature', 'CBAO']):
|
||||||
|
relevant_images.append(img)
|
||||||
|
|
||||||
if image_markdowns:
|
if relevant_images:
|
||||||
# Supprimer les doublons d'images
|
text += "\n\n" + "\n".join(relevant_images)
|
||||||
unique_images = []
|
|
||||||
for img in image_markdowns:
|
|
||||||
if img not in unique_images:
|
|
||||||
unique_images.append(img)
|
|
||||||
|
|
||||||
text += "\n\n" + "\n".join(unique_images)
|
|
||||||
|
|
||||||
# Si on a du contenu, le retourner
|
# Si on a du contenu, le retourner
|
||||||
if text and len(text.strip()) > 5:
|
if text and len(text.strip()) > 5:
|
||||||
return text
|
return text
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
print(f"Erreur lors de l'extraction générique: {e}")
|
logging.error(f"Erreur lors de l'extraction générique: {str(e)}")
|
||||||
|
|
||||||
# Si rien n'a fonctionné mais qu'on a des images, au moins les retourner
|
# 5. Si rien n'a fonctionné mais qu'on a des images, retourner les images
|
||||||
if image_markdowns:
|
if image_markdowns:
|
||||||
unique_images = []
|
# Filtrer les images de signature et logos
|
||||||
|
relevant_images = []
|
||||||
for img in image_markdowns:
|
for img in image_markdowns:
|
||||||
if img not in unique_images:
|
if not any(marker in img for marker in ['logo', 'signature', 'CBAO']):
|
||||||
unique_images.append(img)
|
relevant_images.append(img)
|
||||||
|
|
||||||
if any("Je ne parviens pas à accéder" in html_content for img in image_markdowns):
|
if "Je ne parviens pas à accéder" in html_content and relevant_images:
|
||||||
return "Bonjour,\nJe ne parviens pas à accéder au l'essai au bleu :\n\n" + "\n".join(unique_images) + "\n\nMerci par avance pour votre.\nCordialement"
|
return "Bonjour,\n\nJe ne parviens pas à accéder au l'essai au bleu :\n\n" + "\n".join(relevant_images) + "\n\nMerci par avance pour votre.\n\nCordialement"
|
||||||
else:
|
elif relevant_images:
|
||||||
return "Images extraites :\n\n" + "\n".join(unique_images)
|
return "Images extraites :\n\n" + "\n".join(relevant_images)
|
||||||
|
|
||||||
return "*Contenu non extractible*"
|
return "*Contenu non extractible*"
|
||||||
|
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
print(f"Erreur lors de l'extraction complexe: {e}")
|
logging.error(f"Erreur lors de l'extraction complexe: {str(e)}")
|
||||||
|
|
||||||
# Dernière tentative : extraction directe avec regex
|
# 6. Dernière tentative : extraction directe avec regex
|
||||||
try:
|
try:
|
||||||
# Extraire des images
|
# Extraire des images
|
||||||
image_markdowns = []
|
image_markdowns = []
|
||||||
@ -328,13 +569,28 @@ def extract_from_complex_html(html_content, preserve_images=False):
|
|||||||
# Extraire du texte significatif
|
# Extraire du texte significatif
|
||||||
text_parts = []
|
text_parts = []
|
||||||
|
|
||||||
bonjour_match = re.search(r'<p[^>]*>.*?Bonjour.*?</p>', html_content, re.DOTALL)
|
# Cas spécial pour le message d'accès
|
||||||
if bonjour_match:
|
if "Je ne parviens pas à accéder" in html_content:
|
||||||
text_parts.append(pre_clean_html(bonjour_match.group(0)))
|
for pattern in [
|
||||||
|
r'<p[^>]*>.*?Bonjour.*?</p>',
|
||||||
|
r'<p[^>]*>.*?Je ne parviens pas à accéder.*?</p>',
|
||||||
|
r'<p[^>]*>.*?Merci par avance.*?</p>',
|
||||||
|
r'<p[^>]*>.*?Cordialement.*?</p>'
|
||||||
|
]:
|
||||||
|
match = re.search(pattern, html_content, re.DOTALL)
|
||||||
|
if match:
|
||||||
|
text_parts.append(pre_clean_html(match.group(0)))
|
||||||
|
else:
|
||||||
|
# Extraction générique
|
||||||
|
bonjour_match = re.search(r'<p[^>]*>.*?Bonjour.*?</p>', html_content, re.DOTALL)
|
||||||
|
if bonjour_match:
|
||||||
|
text_parts.append(pre_clean_html(bonjour_match.group(0)))
|
||||||
|
|
||||||
content_match = re.search(r'<p[^>]*>.*?Je ne parviens pas à accéder.*?</p>', html_content, re.DOTALL)
|
# Rechercher d'autres paragraphes significatifs
|
||||||
if content_match:
|
for p_match in re.finditer(r'<p[^>]*>(.*?)</p>', html_content, re.DOTALL):
|
||||||
text_parts.append(pre_clean_html(content_match.group(0)))
|
p_content = p_match.group(1)
|
||||||
|
if len(p_content) > 20 and not re.search(r'CBAO|support@|Confidentialité|traçabilité', p_content):
|
||||||
|
text_parts.append(pre_clean_html(p_match.group(0)))
|
||||||
|
|
||||||
# Combiner texte et images
|
# Combiner texte et images
|
||||||
if text_parts or image_markdowns:
|
if text_parts or image_markdowns:
|
||||||
@ -342,22 +598,25 @@ def extract_from_complex_html(html_content, preserve_images=False):
|
|||||||
if text_parts:
|
if text_parts:
|
||||||
result += "\n".join(text_parts) + "\n\n"
|
result += "\n".join(text_parts) + "\n\n"
|
||||||
|
|
||||||
if image_markdowns:
|
# Filtrer les images de signature et logos
|
||||||
unique_images = []
|
relevant_images = []
|
||||||
for img in image_markdowns:
|
for img in image_markdowns:
|
||||||
if img not in unique_images:
|
if not any(marker in img for marker in ['logo', 'signature', 'CBAO']):
|
||||||
unique_images.append(img)
|
relevant_images.append(img)
|
||||||
result += "\n".join(unique_images)
|
|
||||||
|
if relevant_images:
|
||||||
|
result += "\n".join(relevant_images)
|
||||||
|
|
||||||
return result
|
return result
|
||||||
except Exception:
|
except Exception as e:
|
||||||
pass
|
logging.error(f"Erreur lors de l'extraction par regex: {str(e)}")
|
||||||
|
|
||||||
return "*Contenu non extractible*"
|
return "*Contenu non extractible*"
|
||||||
|
|
||||||
def pre_clean_html(html_content):
|
def pre_clean_html(html_content):
|
||||||
"""
|
"""
|
||||||
Fonction interne pour nettoyer le HTML basique avant traitement avancé.
|
Fonction interne pour nettoyer le HTML basique avant traitement avancé.
|
||||||
|
Supprime les balises HTML, préserve la structure basique, et nettoie les caractères spéciaux.
|
||||||
|
|
||||||
Args:
|
Args:
|
||||||
html_content: Contenu HTML à pré-nettoyer
|
html_content: Contenu HTML à pré-nettoyer
|
||||||
@ -368,41 +627,96 @@ def pre_clean_html(html_content):
|
|||||||
if not html_content:
|
if not html_content:
|
||||||
return ""
|
return ""
|
||||||
|
|
||||||
# Remplacer les balises <br>, <p>, <div> par des sauts de ligne
|
# 1. PRÉSERVATION DES IMAGES
|
||||||
content = html_content.replace('<br>', '\n').replace('<br/>', '\n').replace('<br />', '\n')
|
|
||||||
content = content.replace('</p>', '\n').replace('</div>', '\n')
|
|
||||||
|
|
||||||
# Préserver les URLs des images
|
# Préserver les URLs des images
|
||||||
image_urls = []
|
image_urls = []
|
||||||
img_matches = re.finditer(r'<img[^>]+src=["\']([^"\']+)["\'][^>]*>', content)
|
img_matches = re.finditer(r'<img[^>]+src=["\']([^"\']+)["\'][^>]*>', html_content)
|
||||||
for match in img_matches:
|
for match in img_matches:
|
||||||
if '/web/image/' in match.group(1) or (isinstance(match.group(1), str) and match.group(1).startswith('http')):
|
src = match.group(1)
|
||||||
image_urls.append(match.group(1))
|
if '/web/image/' in src or (isinstance(src, str) and src.startswith('http')):
|
||||||
|
image_urls.append(src)
|
||||||
|
|
||||||
# Supprimer les balises HTML
|
# 2. REMPLACEMENT DES BALISES HTML PAR DES SAUTS DE LIGNE
|
||||||
content = re.sub(r'<[^>]*>', '', content)
|
# Remplacer les balises <br>, <p>, <div>, etc. par des sauts de ligne
|
||||||
|
content = re.sub(r'<br\s*/?>|<p[^>]*>|</p>|<div[^>]*>|</div>', '\n', html_content)
|
||||||
|
|
||||||
# Supprimer les espaces multiples
|
# 3. PRÉSERVATION DU FORMATAGE DE BASE
|
||||||
content = re.sub(r' {2,}', ' ', content)
|
# Préserver le formatage de base (gras, italique, etc.)
|
||||||
|
content = re.sub(r'<(?:b|strong)>(.*?)</(?:b|strong)>', r'**\1**', content)
|
||||||
|
content = re.sub(r'<(?:i|em)>(.*?)</(?:i|em)>', r'*\1*', content)
|
||||||
|
|
||||||
# Supprimer les sauts de ligne multiples
|
# 4. TRANSFORMATION DES LISTES
|
||||||
content = re.sub(r'\n{3,}', '\n\n', content)
|
# Transformer les balises de liste
|
||||||
|
content = re.sub(r'<li>(.*?)</li>', r'- \1\n', content)
|
||||||
|
|
||||||
|
# 5. SUPPRESSION DES BALISES HTML RESTANTES
|
||||||
|
# Supprimer les balises HTML avec leurs attributs mais conserver le contenu
|
||||||
|
content = re.sub(r'<[^>]+>', '', content)
|
||||||
|
|
||||||
|
# 6. NETTOYAGE DES ENTITÉS HTML
|
||||||
# Décoder les entités HTML courantes
|
# Décoder les entités HTML courantes
|
||||||
content = content.replace(' ', ' ')
|
content = html_unescape(content)
|
||||||
content = content.replace('<', '<')
|
|
||||||
content = content.replace('>', '>')
|
|
||||||
content = content.replace('&', '&')
|
|
||||||
content = content.replace('"', '"')
|
|
||||||
|
|
||||||
# Supprimer les tabulations
|
# Alternativement, pour les entités HTML courantes
|
||||||
|
entity_replacements = {
|
||||||
|
' ': ' ',
|
||||||
|
'<': '<',
|
||||||
|
'>': '>',
|
||||||
|
'&': '&',
|
||||||
|
'"': '"',
|
||||||
|
''': "'",
|
||||||
|
''': "'",
|
||||||
|
''': "'",
|
||||||
|
'’': "'",
|
||||||
|
'‘': "'",
|
||||||
|
'“': '"',
|
||||||
|
'”': '"'
|
||||||
|
}
|
||||||
|
|
||||||
|
for entity, replacement in entity_replacements.items():
|
||||||
|
content = content.replace(entity, replacement)
|
||||||
|
|
||||||
|
# 7. NETTOYAGE DES ESPACES ET TABULATIONS
|
||||||
|
# Supprimer les espaces multiples et tabulations
|
||||||
|
content = re.sub(r' {2,}', ' ', content)
|
||||||
content = content.replace('\t', ' ')
|
content = content.replace('\t', ' ')
|
||||||
|
|
||||||
|
# 8. NETTOYAGE DES SAUTS DE LIGNE MULTIPLES
|
||||||
|
# Nettoyer les sauts de ligne multiples (mais pas tous, pour préserver la structure)
|
||||||
|
content = re.sub(r'\n{3,}', '\n\n', content)
|
||||||
|
|
||||||
|
# 9. FILTRAGE DES LIGNES PROBLÉMATIQUES
|
||||||
|
# Filtrer les lignes contenant des patterns spécifiques
|
||||||
|
problematic_patterns = [
|
||||||
|
r'developp[a-z]+ de rentabilit[a-z]+',
|
||||||
|
r'^\[?CBAO.*\]?$',
|
||||||
|
r'^Afin d\'assurer.*tra[cç]abilit[eé]',
|
||||||
|
r'^Support technique',
|
||||||
|
r'^Envoy[eé] par',
|
||||||
|
r'^Ce(tte)? (message|courriel|email).*confidentiel',
|
||||||
|
r'^https?://.*cbao\.fr',
|
||||||
|
r'^Confidentialit[eé]\s*:',
|
||||||
|
r'support@cbao\.fr'
|
||||||
|
]
|
||||||
|
|
||||||
|
filtered_lines = []
|
||||||
|
for line in content.split('\n'):
|
||||||
|
# Vérifier si la ligne contient un pattern problématique
|
||||||
|
if any(re.search(pattern, line, re.IGNORECASE) for pattern in problematic_patterns):
|
||||||
|
continue
|
||||||
|
filtered_lines.append(line)
|
||||||
|
|
||||||
|
content = '\n'.join(filtered_lines)
|
||||||
|
|
||||||
|
# 10. AJOUT DES IMAGES PRÉSERVÉES
|
||||||
# Ajouter les images préservées à la fin
|
# Ajouter les images préservées à la fin
|
||||||
if image_urls:
|
if image_urls:
|
||||||
content += "\n\n"
|
content += "\n\n"
|
||||||
|
seen_urls = set() # Pour éviter les doublons
|
||||||
for url in image_urls:
|
for url in image_urls:
|
||||||
content += f"\n"
|
if url not in seen_urls:
|
||||||
|
content += f"\n"
|
||||||
|
seen_urls.add(url)
|
||||||
|
|
||||||
return content.strip()
|
return content.strip()
|
||||||
|
|
||||||
|
|||||||
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
@ -1,260 +0,0 @@
|
|||||||
TICKET: T11143 - BRGLAB - Essai inaccessible
|
|
||||||
Date d'extraction: 2025-04-16 09:18:58
|
|
||||||
Nombre de messages: 7
|
|
||||||
|
|
||||||
================================================================================
|
|
||||||
|
|
||||||
********************************************************************************
|
|
||||||
*** CHANGEMENT D'ÉTAT ***
|
|
||||||
********************************************************************************
|
|
||||||
|
|
||||||
DATE: 2025-04-03 08:34:43
|
|
||||||
DE: Fabien LAFAY
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
********************************************************************************
|
|
||||||
*** MESSAGE TRANSFÉRÉ ***
|
|
||||||
********************************************************************************
|
|
||||||
|
|
||||||
DATE: 2025-04-03 08:35:20
|
|
||||||
DE: Fabien LAFAY
|
|
||||||
OBJET: Re: [T11143] BRGLAB - Essai inaccessible
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
GIRAUD TP (JCG), Victor BOLLÉE
|
|
||||||
|
|
||||||
|
|
||||||
- il y a 9 minutes
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
À:
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
CBAO S.A.R.L., Quentin FAIVRE
|
|
||||||
;
|
|
||||||
|
|
||||||
|
|
||||||
Fabien LAFAY
|
|
||||||
;
|
|
||||||
|
|
||||||
|
|
||||||
Romuald GRUSON
|
|
||||||
;
|
|
||||||
|
|
||||||
|
|
||||||
support
|
|
||||||
;
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
À:
|
|
||||||
|
|
||||||
support
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
-
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Quentin FAIVRE
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
-
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Fabien LAFAY
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
-
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Romuald GRUSON
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Bonjour,
|
|
||||||
|
|
||||||
Je ne parviens pas à accéder au l’essai au bleu :
|
|
||||||
|
|
||||||
|
|
||||||
Merci par avance pour votre.
|
|
||||||
|
|
||||||
Cordialement
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
********************************************************************************
|
|
||||||
*** CHANGEMENT D'ÉTAT ***
|
|
||||||
********************************************************************************
|
|
||||||
|
|
||||||
DATE: 2025-04-03 09:23:31
|
|
||||||
DE: Fabien LAFAY
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
********************************************************************************
|
|
||||||
*** MESSAGE TRANSFÉRÉ ***
|
|
||||||
********************************************************************************
|
|
||||||
|
|
||||||
DATE: 2025-04-03 12:17:41
|
|
||||||
DE: Fabien LAFAY
|
|
||||||
OBJET: Re: [T11143] - BRGLAB - Essai inaccessible
|
|
||||||
|
|
||||||
Bonjour,Pouvez-vous vérifier si vous avez bien accès à la page suivante en l'ouvrant dans votre navigateur :https://zk1.brg-lab.com/Voici ce que vous devriez voir affiché : Si ce n'est pas le cas, pouvez-vous me faire une capture d'écran de ce qui est affiché?Je reste à votre entière disposition pour toute information complémentaire.Cordialement,---Support technique
|
|
||||||
|
|
||||||
Afin d'assurer une meilleure traçabilité et vous garantir une prise en charge optimale, nous vous invitons à envoyer vos demandes d'assistance technique à support@cbao.frL'objectif du Support Technique est de vous aider : si vous rencontrez une difficulté, ou pour nous soumettre une ou des suggestions d'amélioration de nos logiciels ou de nos méthodes. Notre service est ouvert du lundi au vendredi de 9h à 12h et de 14h à 18h. Dès réception, un technicien prendra en charge votre demande et au besoin vous rappellera.Confidentialité : Ce courriel contient des informations confidentielles exclusivement réservées au destinataire mentionné. Si vous deviez recevoir cet e-mail par erreur, merci d’en avertir immédiatement l’expéditeur et de le supprimer de votre système informatique. Au cas où vous ne seriez pas destinataire de ce message, veuillez noter que sa divulgation, sa copie ou tout acte en rapport avec la communication du contenu des informations est strictement interdit.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
********************************************************************************
|
|
||||||
*** CHANGEMENT D'ÉTAT ***
|
|
||||||
********************************************************************************
|
|
||||||
|
|
||||||
DATE: 2025-04-03 12:17:45
|
|
||||||
DE: Fabien LAFAY
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
********************************************************************************
|
|
||||||
*** MESSAGE TRANSFÉRÉ ***
|
|
||||||
********************************************************************************
|
|
||||||
|
|
||||||
DATE: 2025-04-03 12:21:13
|
|
||||||
DE: Victor BOLLÉE
|
|
||||||
OBJET: TR: [T11143] - BRGLAB - Essai inaccessible
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Bonjour,
|
|
||||||
|
|
||||||
Le problème s’est résolu seul par la suite.
|
|
||||||
|
|
||||||
Je vous remercie pour votre retour.
|
|
||||||
|
|
||||||
Bonne journée
|
|
||||||
|
|
||||||
PS : l’adresse fonctionne
|
|
||||||
|
|
||||||
|
|
||||||
De :
|
|
||||||
support@cbao.fr <support@cbao.fr>
|
|
||||||
|
|
||||||
Envoyé : jeudi 3 avril 2025 14:18
|
|
||||||
À : victor Bollée <v.bollee@labojcg.fr>
|
|
||||||
Objet : Re: [T11143] - BRGLAB - Essai inaccessible
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Voir
|
|
||||||
Tâche
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Bonjour,
|
|
||||||
Pouvez-vous vérifier si vous avez bien accès à la page suivante en l'ouvrant dans votre navigateur :
|
|
||||||
https://zk1.brg-lab.com/
|
|
||||||
Voici ce que vous devriez voir affiché :
|
|
||||||
|
|
||||||
Si ce n'est pas le cas, pouvez-vous me faire une capture d'écran de ce qui est affiché?
|
|
||||||
Je reste à votre entière disposition pour toute information complémentaire.
|
|
||||||
Cordialement,
|
|
||||||
---
|
|
||||||
Support technique
|
|
||||||
|
|
||||||
|
|
||||||
Afin d'assurer une meilleure traçabilité et vous garantir une prise en charge optimale, nous vous invitons à envoyer vos demandes d'assistance
|
|
||||||
technique à support@cbao.fr
|
|
||||||
L'objectif du Support Technique est de vous aider : si vous rencontrez une difficulté, ou pour nous soumettre une ou des suggestions d'amélioration de nos logiciels ou de
|
|
||||||
nos méthodes. Notre service est ouvert du lundi au vendredi de 9h à 12h et de 14h à 18h. Dès réception, un technicien prendra en charge votre demande et au besoin vous rappellera.
|
|
||||||
Confidentialité : Ce courriel contient des informations confidentielles exclusivement réservées au destinataire mentionné. Si vous
|
|
||||||
deviez recevoir cet e-mail par erreur, merci d’en avertir immédiatement l’expéditeur et de le supprimer de votre système informatique. Au cas où vous ne seriez pas destinataire de ce message, veuillez noter que sa divulgation, sa copie ou tout acte en rapport
|
|
||||||
avec la communication du contenu des informations est strictement interdit.
|
|
||||||
|
|
||||||
Envoyé par
|
|
||||||
CBAO S.A.R.L. .
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
********************************************************************************
|
|
||||||
*** CHANGEMENT D'ÉTAT ***
|
|
||||||
********************************************************************************
|
|
||||||
|
|
||||||
DATE: 2025-04-03 12:23:31
|
|
||||||
DE: Fabien LAFAY
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
@ -0,0 +1,41 @@
|
|||||||
|
{
|
||||||
|
"id": "11122",
|
||||||
|
"code": "T11143",
|
||||||
|
"name": "BRGLAB - Essai inaccessible",
|
||||||
|
"description": "*Contenu non extractible*",
|
||||||
|
"project_name": "Demandes",
|
||||||
|
"stage_name": "Clôturé",
|
||||||
|
"user_id": "",
|
||||||
|
"partner_id_email_from": "GIRAUD TP (JCG), Victor BOLLÉE, v.bollee@labojcg.fr",
|
||||||
|
"create_date": "03/04/2025 08:34:43",
|
||||||
|
"write_date_last_modification": "03/04/2025 12:23:31",
|
||||||
|
"date_deadline": "18/04/2025 00:00:00",
|
||||||
|
"messages": [
|
||||||
|
{
|
||||||
|
"author_id": "Fabien LAFAY",
|
||||||
|
"date": "03/04/2025 08:35:20",
|
||||||
|
"message_type": "Système",
|
||||||
|
"subject": "Re: [T11143] BRGLAB - Essai inaccessible",
|
||||||
|
"id": "228942",
|
||||||
|
"content": "GIRAUD TP (JCG), Victor BOLLÉE\n-\nil y a 9 minutes\n;\nFabien LAFAY\n;\nRomuald GRUSON\n;\nsupport\n;\nsupport\n-\nQuentin FAIVRE\n-\nFabien LAFAY\n-\nRomuald GRUSON\nBonjour,\nJe ne parviens pas à accéder au l’essai au bleu :\nMerci par avance pour votre.\nCordialement\n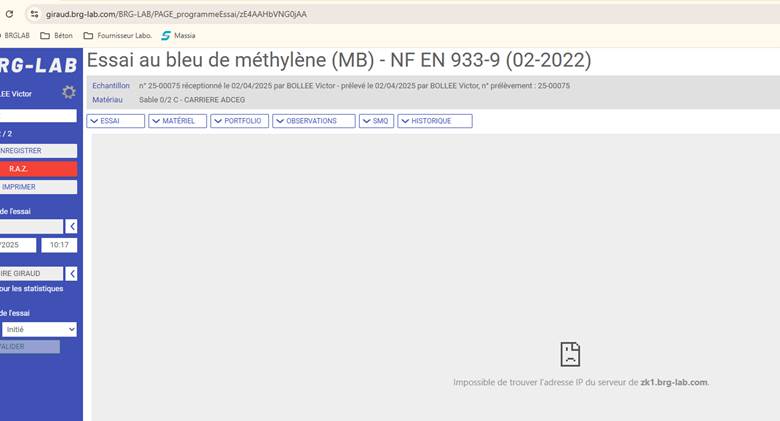\n\n---\n\n"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"author_id": "Fabien LAFAY",
|
||||||
|
"date": "03/04/2025 12:17:41",
|
||||||
|
"message_type": "E-mail",
|
||||||
|
"subject": "Re: [T11143] - BRGLAB - Essai inaccessible",
|
||||||
|
"id": "228968",
|
||||||
|
"content": "Bonjour\n,\nPouvez-vous vérifier si vous avez bien accès à la page suivante en l'ouvrant dans votre navigateur :\nhttps://zk1.brg-lab.com/\nVoici ce que vous devriez voir affiché :\nSi ce n'est pas le cas, pouvez-vous me faire une capture d'écran de ce qui est affiché?\nJe reste à votre entière disposition pour toute information complémentaire.\nCordialement,\n---\nSupport technique\n\n- image.png (image/png) [ID: 145453]\n\n---\n\n"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"author_id": "Victor BOLLÉE",
|
||||||
|
"date": "03/04/2025 12:21:13",
|
||||||
|
"message_type": "E-mail",
|
||||||
|
"subject": "TR: [T11143] - BRGLAB - Essai inaccessible",
|
||||||
|
"id": "228971",
|
||||||
|
"content": "Bonjour,\nLe problème s’est résolu seul par la suite.\nJe vous remercie pour votre retour.\nBonne journée\nPS : l’adresse fonctionne\nDe :\n\n---\n"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"date_d'extraction": "16/04/2025 09:34:39",
|
||||||
|
"répertoire": "output/ticket_T11143/T11143_20250416_093439"
|
||||||
|
}
|
||||||
@ -0,0 +1,93 @@
|
|||||||
|
# Ticket T11143: BRGLAB - Essai inaccessible
|
||||||
|
|
||||||
|
## Informations du ticket
|
||||||
|
|
||||||
|
- **id**: 11122
|
||||||
|
- **code**: T11143
|
||||||
|
- **name**: BRGLAB - Essai inaccessible
|
||||||
|
- **project_name**: Demandes
|
||||||
|
- **stage_name**: Clôturé
|
||||||
|
- **user_id**:
|
||||||
|
- **partner_id/email_from**: GIRAUD TP (JCG), Victor BOLLÉE, v.bollee@labojcg.fr
|
||||||
|
- **create_date**: 03/04/2025 08:34:43
|
||||||
|
- **write_date/last modification**: 03/04/2025 12:23:31
|
||||||
|
- **date_deadline**: 18/04/2025 00:00:00
|
||||||
|
|
||||||
|
- **description**:
|
||||||
|
|
||||||
|
*Contenu non extractible*
|
||||||
|
|
||||||
|
## Messages
|
||||||
|
|
||||||
|
### Message 1
|
||||||
|
**author_id**: Fabien LAFAY
|
||||||
|
**date**: 03/04/2025 08:35:20
|
||||||
|
**message_type**: Système
|
||||||
|
**subject**: Re: [T11143] BRGLAB - Essai inaccessible
|
||||||
|
**id**: 228942
|
||||||
|
GIRAUD TP (JCG), Victor BOLLÉE
|
||||||
|
-
|
||||||
|
il y a 9 minutes
|
||||||
|
;
|
||||||
|
Fabien LAFAY
|
||||||
|
;
|
||||||
|
Romuald GRUSON
|
||||||
|
;
|
||||||
|
support
|
||||||
|
;
|
||||||
|
support
|
||||||
|
-
|
||||||
|
Quentin FAIVRE
|
||||||
|
-
|
||||||
|
Fabien LAFAY
|
||||||
|
-
|
||||||
|
Romuald GRUSON
|
||||||
|
Bonjour,
|
||||||
|
Je ne parviens pas à accéder au l’essai au bleu :
|
||||||
|
Merci par avance pour votre.
|
||||||
|
Cordialement
|
||||||
|

|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Message 2
|
||||||
|
**author_id**: Fabien LAFAY
|
||||||
|
**date**: 03/04/2025 12:17:41
|
||||||
|
**message_type**: E-mail
|
||||||
|
**subject**: Re: [T11143] - BRGLAB - Essai inaccessible
|
||||||
|
**id**: 228968
|
||||||
|
Bonjour
|
||||||
|
,
|
||||||
|
Pouvez-vous vérifier si vous avez bien accès à la page suivante en l'ouvrant dans votre navigateur :
|
||||||
|
https://zk1.brg-lab.com/
|
||||||
|
Voici ce que vous devriez voir affiché :
|
||||||
|
Si ce n'est pas le cas, pouvez-vous me faire une capture d'écran de ce qui est affiché?
|
||||||
|
Je reste à votre entière disposition pour toute information complémentaire.
|
||||||
|
Cordialement,
|
||||||
|
---
|
||||||
|
Support technique
|
||||||
|
|
||||||
|
**attachment_ids**:
|
||||||
|
- image.png (image/png) [ID: 145453]
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Message 3
|
||||||
|
**author_id**: Victor BOLLÉE
|
||||||
|
**date**: 03/04/2025 12:21:13
|
||||||
|
**message_type**: E-mail
|
||||||
|
**subject**: TR: [T11143] - BRGLAB - Essai inaccessible
|
||||||
|
**id**: 228971
|
||||||
|
Bonjour,
|
||||||
|
Le problème s’est résolu seul par la suite.
|
||||||
|
Je vous remercie pour votre retour.
|
||||||
|
Bonne journée
|
||||||
|
PS : l’adresse fonctionne
|
||||||
|
De :
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## Informations sur l'extraction
|
||||||
|
|
||||||
|
- **Date d'extraction**: 16/04/2025 09:34:39
|
||||||
|
- **Répertoire**: output/ticket_T11143/T11143_20250416_093439
|
||||||
@ -7,7 +7,7 @@
|
|||||||
"project_name": "Demandes",
|
"project_name": "Demandes",
|
||||||
"stage_id": 8,
|
"stage_id": 8,
|
||||||
"stage_name": "Clôturé",
|
"stage_name": "Clôturé",
|
||||||
"date_extraction": "2025-04-16T09:18:58.395055"
|
"date_extraction": "2025-04-16T09:34:39.776257"
|
||||||
},
|
},
|
||||||
"metadata": {
|
"metadata": {
|
||||||
"message_count": {
|
"message_count": {
|
||||||
@ -66,7 +66,7 @@
|
|||||||
},
|
},
|
||||||
{
|
{
|
||||||
"id": 228942,
|
"id": 228942,
|
||||||
"body": "\n\n GIRAUD TP (JCG), Victor BOLLÉE\n \n\n - il y a 9 minutes\n\n\n\n\n\n\n\n\n\n\n \n À: \n \n \n \nCBAO S.A.R.L., Quentin FAIVRE\n ; \n \n\nFabien LAFAY\n ; \n \n\nRomuald GRUSON\n ; \n \n\nsupport\n ; \n \n\n\n\nÀ:\n\n support\n \n\n\n\n\n\n \n \n -\n \n \n \n Quentin FAIVRE\n \n\n\n\n\n\n \n \n -\n \n \n \n Fabien LAFAY\n \n\n\n\n\n\n \n \n -\n \n \n \n Romuald GRUSON\n \n\n\n\n\n\n\n\n\n\n\nBonjour,\n \nJe ne parviens pas à accéder au l’essai au bleu :\n\n \nMerci par avance pour votre.\n \nCordialement",
|
"body": "GIRAUD TP (JCG), Victor BOLLÉE\n-\nil y a 9 minutes\n;\nFabien LAFAY\n;\nRomuald GRUSON\n;\nsupport\n;\nsupport\n-\nQuentin FAIVRE\n-\nFabien LAFAY\n-\nRomuald GRUSON\nBonjour,\nJe ne parviens pas à accéder au l’essai au bleu :\nMerci par avance pour votre.\nCordialement\n\n\n",
|
||||||
"date": "2025-04-03 08:35:20",
|
"date": "2025-04-03 08:35:20",
|
||||||
"author_id": [
|
"author_id": [
|
||||||
28961,
|
28961,
|
||||||
@ -145,7 +145,7 @@
|
|||||||
},
|
},
|
||||||
{
|
{
|
||||||
"id": 228968,
|
"id": 228968,
|
||||||
"body": "Bonjour,Pouvez-vous vérifier si vous avez bien accès à la page suivante en l'ouvrant dans votre navigateur :https://zk1.brg-lab.com/Voici ce que vous devriez voir affiché : Si ce n'est pas le cas, pouvez-vous me faire une capture d'écran de ce qui est affiché?Je reste à votre entière disposition pour toute information complémentaire.Cordialement,---Support technique \n\nAfin d'assurer une meilleure traçabilité et vous garantir une prise en charge optimale, nous vous invitons à envoyer vos demandes d'assistance technique à support@cbao.frL'objectif du Support Technique est de vous aider : si vous rencontrez une difficulté, ou pour nous soumettre une ou des suggestions d'amélioration de nos logiciels ou de nos méthodes. Notre service est ouvert du lundi au vendredi de 9h à 12h et de 14h à 18h. Dès réception, un technicien prendra en charge votre demande et au besoin vous rappellera.Confidentialité : Ce courriel contient des informations confidentielles exclusivement réservées au destinataire mentionné. Si vous deviez recevoir cet e-mail par erreur, merci d’en avertir immédiatement l’expéditeur et de le supprimer de votre système informatique. Au cas où vous ne seriez pas destinataire de ce message, veuillez noter que sa divulgation, sa copie ou tout acte en rapport avec la communication du contenu des informations est strictement interdit.",
|
"body": "Bonjour\n,\nPouvez-vous vérifier si vous avez bien accès à la page suivante en l'ouvrant dans votre navigateur :\nhttps://zk1.brg-lab.com/\nVoici ce que vous devriez voir affiché :\nSi ce n'est pas le cas, pouvez-vous me faire une capture d'écran de ce qui est affiché?\nJe reste à votre entière disposition pour toute information complémentaire.\nCordialement,\n---\nSupport technique",
|
||||||
"date": "2025-04-03 12:17:41",
|
"date": "2025-04-03 12:17:41",
|
||||||
"author_id": [
|
"author_id": [
|
||||||
28961,
|
28961,
|
||||||
@ -227,7 +227,7 @@
|
|||||||
},
|
},
|
||||||
{
|
{
|
||||||
"id": 228971,
|
"id": 228971,
|
||||||
"body": "\n\nBonjour,\n \nLe problème s’est résolu seul par la suite.\n \nJe vous remercie pour votre retour.\n \nBonne journée\n \nPS : l’adresse fonctionne\n \n\nDe :\nsupport@cbao.fr <support@cbao.fr>\r\n\nEnvoyé : jeudi 3 avril 2025 14:18\nÀ : victor Bollée <v.bollee@labojcg.fr>\nObjet : Re: [T11143] - BRGLAB - Essai inaccessible\n\n \n\n\n\n\n\n\n\nVoir\r\n Tâche \n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nBonjour,\nPouvez-vous vérifier si vous avez bien accès à la page suivante en l'ouvrant dans votre navigateur :\nhttps://zk1.brg-lab.com/\nVoici ce que vous devriez voir affiché : \n\nSi ce n'est pas le cas, pouvez-vous me faire une capture d'écran de ce qui est affiché?\nJe reste à votre entière disposition pour toute information complémentaire.\nCordialement,\n---\nSupport technique\r\n \n\nAfin d'assurer une meilleure traçabilité et vous garantir une prise en charge optimale, nous vous invitons à envoyer vos demandes d'assistance\r\n technique à support@cbao.fr\nL'objectif du Support Technique est de vous aider : si vous rencontrez une difficulté, ou pour nous soumettre une ou des suggestions d'amélioration de nos logiciels ou de\r\n nos méthodes. Notre service est ouvert du lundi au vendredi de 9h à 12h et de 14h à 18h. Dès réception, un technicien prendra en charge votre demande et au besoin vous rappellera.\nConfidentialité : Ce courriel contient des informations confidentielles exclusivement réservées au destinataire mentionné. Si vous\r\n deviez recevoir cet e-mail par erreur, merci d’en avertir immédiatement l’expéditeur et de le supprimer de votre système informatique. Au cas où vous ne seriez pas destinataire de ce message, veuillez noter que sa divulgation, sa copie ou tout acte en rapport\r\n avec la communication du contenu des informations est strictement interdit.\n\nEnvoyé par \nCBAO S.A.R.L. . \n\n\n\n\n",
|
"body": "Bonjour,\nLe problème s’est résolu seul par la suite.\nJe vous remercie pour votre retour.\nBonne journée\nPS : l’adresse fonctionne\nDe :",
|
||||||
"date": "2025-04-03 12:21:13",
|
"date": "2025-04-03 12:21:13",
|
||||||
"author_id": [
|
"author_id": [
|
||||||
28897,
|
28897,
|
||||||
122
output/ticket_T11143/T11143_20250416_093439/all_messages.txt
Normal file
122
output/ticket_T11143/T11143_20250416_093439/all_messages.txt
Normal file
@ -0,0 +1,122 @@
|
|||||||
|
TICKET: T11143 - BRGLAB - Essai inaccessible
|
||||||
|
Date d'extraction: 2025-04-16 09:34:39
|
||||||
|
Nombre de messages: 7
|
||||||
|
|
||||||
|
================================================================================
|
||||||
|
|
||||||
|
********************************************************************************
|
||||||
|
*** CHANGEMENT D'ÉTAT ***
|
||||||
|
********************************************************************************
|
||||||
|
|
||||||
|
DATE: 2025-04-03 08:34:43
|
||||||
|
DE: Fabien LAFAY
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
********************************************************************************
|
||||||
|
*** MESSAGE TRANSFÉRÉ ***
|
||||||
|
********************************************************************************
|
||||||
|
|
||||||
|
DATE: 2025-04-03 08:35:20
|
||||||
|
DE: Fabien LAFAY
|
||||||
|
OBJET: Re: [T11143] BRGLAB - Essai inaccessible
|
||||||
|
|
||||||
|
GIRAUD TP (JCG), Victor BOLLÉE
|
||||||
|
-
|
||||||
|
il y a 9 minutes
|
||||||
|
;
|
||||||
|
Fabien LAFAY
|
||||||
|
;
|
||||||
|
Romuald GRUSON
|
||||||
|
;
|
||||||
|
support
|
||||||
|
;
|
||||||
|
support
|
||||||
|
-
|
||||||
|
Quentin FAIVRE
|
||||||
|
-
|
||||||
|
Fabien LAFAY
|
||||||
|
-
|
||||||
|
Romuald GRUSON
|
||||||
|
Bonjour,
|
||||||
|
Je ne parviens pas à accéder au l’essai au bleu :
|
||||||
|
Merci par avance pour votre.
|
||||||
|
Cordialement
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
********************************************************************************
|
||||||
|
*** CHANGEMENT D'ÉTAT ***
|
||||||
|
********************************************************************************
|
||||||
|
|
||||||
|
DATE: 2025-04-03 09:23:31
|
||||||
|
DE: Fabien LAFAY
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
********************************************************************************
|
||||||
|
*** MESSAGE TRANSFÉRÉ ***
|
||||||
|
********************************************************************************
|
||||||
|
|
||||||
|
DATE: 2025-04-03 12:17:41
|
||||||
|
DE: Fabien LAFAY
|
||||||
|
OBJET: Re: [T11143] - BRGLAB - Essai inaccessible
|
||||||
|
|
||||||
|
Bonjour
|
||||||
|
,
|
||||||
|
Pouvez-vous vérifier si vous avez bien accès à la page suivante en l'ouvrant dans votre navigateur :
|
||||||
|
https://zk1.brg-lab.com/
|
||||||
|
Voici ce que vous devriez voir affiché :
|
||||||
|
Si ce n'est pas le cas, pouvez-vous me faire une capture d'écran de ce qui est affiché?
|
||||||
|
Je reste à votre entière disposition pour toute information complémentaire.
|
||||||
|
Cordialement,
|
||||||
|
---
|
||||||
|
Support technique
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
********************************************************************************
|
||||||
|
*** CHANGEMENT D'ÉTAT ***
|
||||||
|
********************************************************************************
|
||||||
|
|
||||||
|
DATE: 2025-04-03 12:17:45
|
||||||
|
DE: Fabien LAFAY
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
********************************************************************************
|
||||||
|
*** MESSAGE TRANSFÉRÉ ***
|
||||||
|
********************************************************************************
|
||||||
|
|
||||||
|
DATE: 2025-04-03 12:21:13
|
||||||
|
DE: Victor BOLLÉE
|
||||||
|
OBJET: TR: [T11143] - BRGLAB - Essai inaccessible
|
||||||
|
|
||||||
|
Bonjour,
|
||||||
|
Le problème s’est résolu seul par la suite.
|
||||||
|
Je vous remercie pour votre retour.
|
||||||
|
Bonne journée
|
||||||
|
PS : l’adresse fonctionne
|
||||||
|
De :
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
********************************************************************************
|
||||||
|
*** CHANGEMENT D'ÉTAT ***
|
||||||
|
********************************************************************************
|
||||||
|
|
||||||
|
DATE: 2025-04-03 12:23:31
|
||||||
|
DE: Fabien LAFAY
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
{kind=link}
|
Before Width: | Height: | Size: 75 KiB After Width: | Height: | Size: 75 KiB |
@ -14,7 +14,7 @@
|
|||||||
"creator_name": "Fabien LAFAY",
|
"creator_name": "Fabien LAFAY",
|
||||||
"creator_id": 22,
|
"creator_id": 22,
|
||||||
"download_status": "success",
|
"download_status": "success",
|
||||||
"local_path": "output/ticket_T11143/T11143_20250416_091857/attachments/image.png",
|
"local_path": "output/ticket_T11143/T11143_20250416_093439/attachments/image.png",
|
||||||
"error": ""
|
"error": ""
|
||||||
}
|
}
|
||||||
]
|
]
|
||||||
@ -1,7 +1,7 @@
|
|||||||
{
|
{
|
||||||
"timestamp": "20250416_091857",
|
"timestamp": "20250416_093439",
|
||||||
"ticket_code": "T11143",
|
"ticket_code": "T11143",
|
||||||
"output_directory": "output/ticket_T11143/T11143_20250416_091857",
|
"output_directory": "output/ticket_T11143/T11143_20250416_093439",
|
||||||
"message_count": 7,
|
"message_count": 7,
|
||||||
"attachment_count": 1,
|
"attachment_count": 1,
|
||||||
"files_created": [
|
"files_created": [
|
||||||
@ -1,9 +1,9 @@
|
|||||||
{
|
{
|
||||||
"date_extraction": "2025-04-16T09:18:58.496625",
|
"date_extraction": "2025-04-16T09:34:39.880507",
|
||||||
"ticket_id": 11122,
|
"ticket_id": 11122,
|
||||||
"ticket_code": "T11143",
|
"ticket_code": "T11143",
|
||||||
"ticket_name": "BRGLAB - Essai inaccessible",
|
"ticket_name": "BRGLAB - Essai inaccessible",
|
||||||
"output_dir": "output/ticket_T11143/T11143_20250416_091857",
|
"output_dir": "output/ticket_T11143/T11143_20250416_093439",
|
||||||
"files": {
|
"files": {
|
||||||
"ticket_info": "ticket_info.json",
|
"ticket_info": "ticket_info.json",
|
||||||
"ticket_summary": "ticket_summary.json",
|
"ticket_summary": "ticket_summary.json",
|
||||||
@ -0,0 +1,25 @@
|
|||||||
|
{
|
||||||
|
"id": "9635",
|
||||||
|
"code": "T9656",
|
||||||
|
"name": "Gestion des utilisateurs",
|
||||||
|
"description": "Point particulier :\nMulti laboratoire :tous\nLe cas n'est pas bloquant\nDescription du problème :\nBonjour,\n\nDans le menu Mes paramètres - Gestion des utilisateurs, tous les utilisateurs n'apparaissent pas. Comment faire pour les faire tous apparaitre?\nMerci.",
|
||||||
|
"project_name": "Demandes",
|
||||||
|
"stage_name": "Clôturé",
|
||||||
|
"user_id": "",
|
||||||
|
"partner_id_email_from": "CHAUSSON MATERIAUX, Christophe SAUVAGET, christophe.sauvaget@chausson.fr",
|
||||||
|
"create_date": "04/07/2024 12:09:47",
|
||||||
|
"write_date_last_modification": "03/10/2024 13:10:50",
|
||||||
|
"date_deadline": "19/07/2024 00:00:00",
|
||||||
|
"messages": [
|
||||||
|
{
|
||||||
|
"author_id": "Fabien LAFAY",
|
||||||
|
"date": "04/07/2024 13:03:58",
|
||||||
|
"message_type": "E-mail",
|
||||||
|
"subject": "Re: [T9656] - Gestion des utilisateurs",
|
||||||
|
"id": "191104",
|
||||||
|
"content": "Bonjour,\nSi un utilisateur n'apparait pas dans la liste, c'est probablement car il n'a pas de laboratoire principal d'assigné.\nDans ce cas, il faut cocher la case \"Affiche les laboratoires secondaires\" pour le voir.\nVous pouvez ensuite retrouver l'utilisateur dans la liste (en utilisant les filtre sur les colonnes si besoin) et l'éditer.\nSur la fiche de l'utilisateur, vérifier si le laboratoire principal est présent, et ajoutez-le si ce n'est pas le cas.\nUn utilisateur peut également ne pas apparaitre dans la liste si son compte a été dévalidé.\nDans ce cas cochez la case \"Affiche les utilisateurs non valides\" pour le voir apparaitre dans la liste (en grisé).\nVous pouvez le rendre à nouveau valide en éditant son compte et en cochant la case \"Utilisateur valide\"\nJe reste à votre entière disposition pour toute information complémentaire.\nCordialement,\nPour vous accompagner au mieux, veuillez trouver ci-joint des liens d'aide :\nManuel d'utilisation :\nlien vers le manuel d'utilisation\n\n- image.png (image/png) [ID: 129046]\n- image.png (image/png) [ID: 129044]\n- image.png (image/png) [ID: 129042]\n\n---\n"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"date_d'extraction": "16/04/2025 09:35:18",
|
||||||
|
"répertoire": "output/ticket_T9656/T9656_20250416_093517"
|
||||||
|
}
|
||||||
@ -0,0 +1,59 @@
|
|||||||
|
# Ticket T9656: Gestion des utilisateurs
|
||||||
|
|
||||||
|
## Informations du ticket
|
||||||
|
|
||||||
|
- **id**: 9635
|
||||||
|
- **code**: T9656
|
||||||
|
- **name**: Gestion des utilisateurs
|
||||||
|
- **project_name**: Demandes
|
||||||
|
- **stage_name**: Clôturé
|
||||||
|
- **user_id**:
|
||||||
|
- **partner_id/email_from**: CHAUSSON MATERIAUX, Christophe SAUVAGET, christophe.sauvaget@chausson.fr
|
||||||
|
- **create_date**: 04/07/2024 12:09:47
|
||||||
|
- **write_date/last modification**: 03/10/2024 13:10:50
|
||||||
|
- **date_deadline**: 19/07/2024 00:00:00
|
||||||
|
|
||||||
|
- **description**:
|
||||||
|
|
||||||
|
Point particulier :
|
||||||
|
Multi laboratoire :tous
|
||||||
|
Le cas n'est pas bloquant
|
||||||
|
Description du problème :
|
||||||
|
Bonjour,
|
||||||
|
|
||||||
|
Dans le menu Mes paramètres - Gestion des utilisateurs, tous les utilisateurs n'apparaissent pas. Comment faire pour les faire tous apparaitre?
|
||||||
|
Merci.
|
||||||
|
|
||||||
|
## Messages
|
||||||
|
|
||||||
|
### Message 1
|
||||||
|
**author_id**: Fabien LAFAY
|
||||||
|
**date**: 04/07/2024 13:03:58
|
||||||
|
**message_type**: E-mail
|
||||||
|
**subject**: Re: [T9656] - Gestion des utilisateurs
|
||||||
|
**id**: 191104
|
||||||
|
Bonjour,
|
||||||
|
Si un utilisateur n'apparait pas dans la liste, c'est probablement car il n'a pas de laboratoire principal d'assigné.
|
||||||
|
Dans ce cas, il faut cocher la case "Affiche les laboratoires secondaires" pour le voir.
|
||||||
|
Vous pouvez ensuite retrouver l'utilisateur dans la liste (en utilisant les filtre sur les colonnes si besoin) et l'éditer.
|
||||||
|
Sur la fiche de l'utilisateur, vérifier si le laboratoire principal est présent, et ajoutez-le si ce n'est pas le cas.
|
||||||
|
Un utilisateur peut également ne pas apparaitre dans la liste si son compte a été dévalidé.
|
||||||
|
Dans ce cas cochez la case "Affiche les utilisateurs non valides" pour le voir apparaitre dans la liste (en grisé).
|
||||||
|
Vous pouvez le rendre à nouveau valide en éditant son compte et en cochant la case "Utilisateur valide"
|
||||||
|
Je reste à votre entière disposition pour toute information complémentaire.
|
||||||
|
Cordialement,
|
||||||
|
Pour vous accompagner au mieux, veuillez trouver ci-joint des liens d'aide :
|
||||||
|
Manuel d'utilisation :
|
||||||
|
lien vers le manuel d'utilisation
|
||||||
|
|
||||||
|
**attachment_ids**:
|
||||||
|
- image.png (image/png) [ID: 129046]
|
||||||
|
- image.png (image/png) [ID: 129044]
|
||||||
|
- image.png (image/png) [ID: 129042]
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## Informations sur l'extraction
|
||||||
|
|
||||||
|
- **Date d'extraction**: 16/04/2025 09:35:18
|
||||||
|
- **Répertoire**: output/ticket_T9656/T9656_20250416_093517
|
||||||
232
output/ticket_T9656/T9656_20250416_093517/all_messages.json
Normal file
232
output/ticket_T9656/T9656_20250416_093517/all_messages.json
Normal file
File diff suppressed because one or more lines are too long
73
output/ticket_T9656/T9656_20250416_093517/all_messages.txt
Normal file
73
output/ticket_T9656/T9656_20250416_093517/all_messages.txt
Normal file
@ -0,0 +1,73 @@
|
|||||||
|
TICKET: T9656 - Gestion des utilisateurs
|
||||||
|
Date d'extraction: 2025-04-16 09:35:18
|
||||||
|
Nombre de messages: 5
|
||||||
|
|
||||||
|
================================================================================
|
||||||
|
|
||||||
|
********************************************************************************
|
||||||
|
*** CHANGEMENT D'ÉTAT ***
|
||||||
|
********************************************************************************
|
||||||
|
|
||||||
|
DATE: 2024-07-04 12:09:47
|
||||||
|
DE: Support Robot
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
********************************************************************************
|
||||||
|
*** CHANGEMENT D'ÉTAT ***
|
||||||
|
********************************************************************************
|
||||||
|
|
||||||
|
DATE: 2024-07-04 12:42:43
|
||||||
|
DE: Fabien LAFAY
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
********************************************************************************
|
||||||
|
*** MESSAGE TRANSFÉRÉ ***
|
||||||
|
********************************************************************************
|
||||||
|
|
||||||
|
DATE: 2024-07-04 13:03:58
|
||||||
|
DE: Fabien LAFAY
|
||||||
|
OBJET: Re: [T9656] - Gestion des utilisateurs
|
||||||
|
|
||||||
|
Bonjour,
|
||||||
|
Si un utilisateur n'apparait pas dans la liste, c'est probablement car il n'a pas de laboratoire principal d'assigné.
|
||||||
|
Dans ce cas, il faut cocher la case "Affiche les laboratoires secondaires" pour le voir.
|
||||||
|
Vous pouvez ensuite retrouver l'utilisateur dans la liste (en utilisant les filtre sur les colonnes si besoin) et l'éditer.
|
||||||
|
Sur la fiche de l'utilisateur, vérifier si le laboratoire principal est présent, et ajoutez-le si ce n'est pas le cas.
|
||||||
|
Un utilisateur peut également ne pas apparaitre dans la liste si son compte a été dévalidé.
|
||||||
|
Dans ce cas cochez la case "Affiche les utilisateurs non valides" pour le voir apparaitre dans la liste (en grisé).
|
||||||
|
Vous pouvez le rendre à nouveau valide en éditant son compte et en cochant la case "Utilisateur valide"
|
||||||
|
Je reste à votre entière disposition pour toute information complémentaire.
|
||||||
|
Cordialement,
|
||||||
|
Pour vous accompagner au mieux, veuillez trouver ci-joint des liens d'aide :
|
||||||
|
Manuel d'utilisation :
|
||||||
|
lien vers le manuel d'utilisation
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
********************************************************************************
|
||||||
|
*** CHANGEMENT D'ÉTAT ***
|
||||||
|
********************************************************************************
|
||||||
|
|
||||||
|
DATE: 2024-07-04 13:04:02
|
||||||
|
DE: Fabien LAFAY
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
********************************************************************************
|
||||||
|
*** CHANGEMENT D'ÉTAT ***
|
||||||
|
********************************************************************************
|
||||||
|
|
||||||
|
DATE: 2024-07-19 08:00:10
|
||||||
|
DE: Fabien LAFAY
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
BIN
output/ticket_T9656/T9656_20250416_093517/attachments/image.png
Normal file
BIN
output/ticket_T9656/T9656_20250416_093517/attachments/image.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 44 KiB |
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 25 KiB |
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 45 KiB |
@ -0,0 +1,56 @@
|
|||||||
|
[
|
||||||
|
{
|
||||||
|
"id": 129046,
|
||||||
|
"name": "image.png",
|
||||||
|
"mimetype": "image/png",
|
||||||
|
"file_size": 44511,
|
||||||
|
"create_date": "2024-07-04 13:03:58",
|
||||||
|
"create_uid": [
|
||||||
|
22,
|
||||||
|
"Fabien LAFAY"
|
||||||
|
],
|
||||||
|
"description": false,
|
||||||
|
"res_name": "[T9656] Gestion des utilisateurs",
|
||||||
|
"creator_name": "Fabien LAFAY",
|
||||||
|
"creator_id": 22,
|
||||||
|
"download_status": "success",
|
||||||
|
"local_path": "output/ticket_T9656/T9656_20250416_093517/attachments/image.png",
|
||||||
|
"error": ""
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"id": 129044,
|
||||||
|
"name": "image.png",
|
||||||
|
"mimetype": "image/png",
|
||||||
|
"file_size": 25583,
|
||||||
|
"create_date": "2024-07-04 13:03:58",
|
||||||
|
"create_uid": [
|
||||||
|
22,
|
||||||
|
"Fabien LAFAY"
|
||||||
|
],
|
||||||
|
"description": false,
|
||||||
|
"res_name": "[T9656] Gestion des utilisateurs",
|
||||||
|
"creator_name": "Fabien LAFAY",
|
||||||
|
"creator_id": 22,
|
||||||
|
"download_status": "success",
|
||||||
|
"local_path": "output/ticket_T9656/T9656_20250416_093517/attachments/image_1.png",
|
||||||
|
"error": ""
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"id": 129042,
|
||||||
|
"name": "image.png",
|
||||||
|
"mimetype": "image/png",
|
||||||
|
"file_size": 46468,
|
||||||
|
"create_date": "2024-07-04 13:03:58",
|
||||||
|
"create_uid": [
|
||||||
|
22,
|
||||||
|
"Fabien LAFAY"
|
||||||
|
],
|
||||||
|
"description": false,
|
||||||
|
"res_name": "[T9656] Gestion des utilisateurs",
|
||||||
|
"creator_name": "Fabien LAFAY",
|
||||||
|
"creator_id": 22,
|
||||||
|
"download_status": "success",
|
||||||
|
"local_path": "output/ticket_T9656/T9656_20250416_093517/attachments/image_2.png",
|
||||||
|
"error": ""
|
||||||
|
}
|
||||||
|
]
|
||||||
@ -0,0 +1,13 @@
|
|||||||
|
{
|
||||||
|
"timestamp": "20250416_093517",
|
||||||
|
"ticket_code": "T9656",
|
||||||
|
"output_directory": "output/ticket_T9656/T9656_20250416_093517",
|
||||||
|
"message_count": 5,
|
||||||
|
"attachment_count": 3,
|
||||||
|
"files_created": [
|
||||||
|
"ticket_info.json",
|
||||||
|
"ticket_summary.json",
|
||||||
|
"all_messages.json",
|
||||||
|
"structure.json"
|
||||||
|
]
|
||||||
|
}
|
||||||
16
output/ticket_T9656/T9656_20250416_093517/followers.json
Normal file
16
output/ticket_T9656/T9656_20250416_093517/followers.json
Normal file
@ -0,0 +1,16 @@
|
|||||||
|
[
|
||||||
|
{
|
||||||
|
"id": 76486,
|
||||||
|
"partner_id": [
|
||||||
|
28961,
|
||||||
|
"Fabien LAFAY"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"id": 76493,
|
||||||
|
"partner_id": [
|
||||||
|
29511,
|
||||||
|
"CHAUSSON MATERIAUX, Christophe SAUVAGET"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
]
|
||||||
218
output/ticket_T9656/T9656_20250416_093517/messages_raw.json
Normal file
218
output/ticket_T9656/T9656_20250416_093517/messages_raw.json
Normal file
File diff suppressed because one or more lines are too long
20
output/ticket_T9656/T9656_20250416_093517/structure.json
Normal file
20
output/ticket_T9656/T9656_20250416_093517/structure.json
Normal file
@ -0,0 +1,20 @@
|
|||||||
|
{
|
||||||
|
"date_extraction": "2025-04-16T09:35:18.659900",
|
||||||
|
"ticket_id": 9635,
|
||||||
|
"ticket_code": "T9656",
|
||||||
|
"ticket_name": "Gestion des utilisateurs",
|
||||||
|
"output_dir": "output/ticket_T9656/T9656_20250416_093517",
|
||||||
|
"files": {
|
||||||
|
"ticket_info": "ticket_info.json",
|
||||||
|
"ticket_summary": "ticket_summary.json",
|
||||||
|
"messages": "all_messages.json",
|
||||||
|
"messages_raw": "messages_raw.json",
|
||||||
|
"messages_text": "all_messages.txt",
|
||||||
|
"attachments": "attachments_info.json",
|
||||||
|
"followers": "followers.json"
|
||||||
|
},
|
||||||
|
"stats": {
|
||||||
|
"messages_count": 5,
|
||||||
|
"attachments_count": 3
|
||||||
|
}
|
||||||
|
}
|
||||||
54
output/ticket_T9656/T9656_20250416_093517/ticket_info.json
Normal file
54
output/ticket_T9656/T9656_20250416_093517/ticket_info.json
Normal file
@ -0,0 +1,54 @@
|
|||||||
|
{
|
||||||
|
"id": 9635,
|
||||||
|
"name": "Gestion des utilisateurs",
|
||||||
|
"description": "<h1>Point particulier :</h1><ul><li>Multi laboratoire :tous</li><li>Le cas n'est pas bloquant</li></ul><h1>Description du problème :</h1><p>Bonjour,\r\n\r\nDans le menu Mes paramètres - Gestion des utilisateurs, tous les utilisateurs n'apparaissent pas. Comment faire pour les faire tous apparaitre?\r\nMerci.</p>",
|
||||||
|
"stage_id": [
|
||||||
|
8,
|
||||||
|
"Clôturé"
|
||||||
|
],
|
||||||
|
"project_id": [
|
||||||
|
3,
|
||||||
|
"Demandes"
|
||||||
|
],
|
||||||
|
"partner_id": [
|
||||||
|
29511,
|
||||||
|
"CHAUSSON MATERIAUX, Christophe SAUVAGET"
|
||||||
|
],
|
||||||
|
"user_id": [
|
||||||
|
22,
|
||||||
|
"Fabien LAFAY"
|
||||||
|
],
|
||||||
|
"date_start": "2024-07-04 12:09:47",
|
||||||
|
"date_end": false,
|
||||||
|
"date_deadline": "2024-07-19",
|
||||||
|
"create_date": "2024-07-04 12:09:47",
|
||||||
|
"write_date": "2024-10-03 13:10:50",
|
||||||
|
"tag_ids": [
|
||||||
|
15
|
||||||
|
],
|
||||||
|
"priority": "1",
|
||||||
|
"email_from": "christophe.sauvaget@chausson.fr",
|
||||||
|
"email_cc": "",
|
||||||
|
"message_ids": [
|
||||||
|
193689,
|
||||||
|
191107,
|
||||||
|
191106,
|
||||||
|
191105,
|
||||||
|
191104,
|
||||||
|
191097,
|
||||||
|
191085
|
||||||
|
],
|
||||||
|
"message_follower_ids": [
|
||||||
|
76486,
|
||||||
|
76493
|
||||||
|
],
|
||||||
|
"timesheet_ids": [],
|
||||||
|
"attachment_ids": [],
|
||||||
|
"stage_id_name": "Clôturé",
|
||||||
|
"project_id_name": "Demandes",
|
||||||
|
"partner_id_name": "CHAUSSON MATERIAUX, Christophe SAUVAGET",
|
||||||
|
"user_id_name": "Fabien LAFAY",
|
||||||
|
"tag_names": [
|
||||||
|
"BRG-LAB WEB"
|
||||||
|
]
|
||||||
|
}
|
||||||
@ -0,0 +1,16 @@
|
|||||||
|
{
|
||||||
|
"id": 9635,
|
||||||
|
"code": "T9656",
|
||||||
|
"name": "Gestion des utilisateurs",
|
||||||
|
"description": "<h1>Point particulier :</h1><ul><li>Multi laboratoire :tous</li><li>Le cas n'est pas bloquant</li></ul><h1>Description du problème :</h1><p>Bonjour,\r\n\r\nDans le menu Mes paramètres - Gestion des utilisateurs, tous les utilisateurs n'apparaissent pas. Comment faire pour les faire tous apparaitre?\r\nMerci.</p>",
|
||||||
|
"stage": "Clôturé",
|
||||||
|
"project": "Demandes",
|
||||||
|
"partner": "CHAUSSON MATERIAUX, Christophe SAUVAGET",
|
||||||
|
"assigned_to": "Fabien LAFAY",
|
||||||
|
"tags": [
|
||||||
|
"BRG-LAB WEB"
|
||||||
|
],
|
||||||
|
"create_date": "2024-07-04 12:09:47",
|
||||||
|
"write_date": "2024-10-03 13:10:50",
|
||||||
|
"deadline": "2024-07-19"
|
||||||
|
}
|
||||||
@ -206,3 +206,27 @@
|
|||||||
2025-04-16 09:18:58 - root - INFO - Messages traités: 7
|
2025-04-16 09:18:58 - root - INFO - Messages traités: 7
|
||||||
2025-04-16 09:18:58 - root - INFO - Pièces jointes: 1
|
2025-04-16 09:18:58 - root - INFO - Pièces jointes: 1
|
||||||
2025-04-16 09:18:58 - root - INFO - ------------------------------------------------------------
|
2025-04-16 09:18:58 - root - INFO - ------------------------------------------------------------
|
||||||
|
2025-04-16 09:34:39 - root - INFO - Extraction du ticket T11143
|
||||||
|
2025-04-16 09:34:39 - root - INFO - ------------------------------------------------------------
|
||||||
|
2025-04-16 09:34:39 - root - INFO - Traitement de 1 pièces jointes pour le ticket 11122
|
||||||
|
2025-04-16 09:34:39 - root - INFO - Pièce jointe téléchargée: image.png (1/1)
|
||||||
|
2025-04-16 09:34:39 - root - INFO - ------------------------------------------------------------
|
||||||
|
2025-04-16 09:34:39 - root - INFO - Extraction terminée avec succès
|
||||||
|
2025-04-16 09:34:39 - root - INFO - Ticket: T11143
|
||||||
|
2025-04-16 09:34:39 - root - INFO - Répertoire: output/ticket_T11143/T11143_20250416_093439
|
||||||
|
2025-04-16 09:34:39 - root - INFO - Messages traités: 7
|
||||||
|
2025-04-16 09:34:39 - root - INFO - Pièces jointes: 1
|
||||||
|
2025-04-16 09:34:39 - root - INFO - ------------------------------------------------------------
|
||||||
|
2025-04-16 09:35:17 - root - INFO - Extraction du ticket T9656
|
||||||
|
2025-04-16 09:35:17 - root - INFO - ------------------------------------------------------------
|
||||||
|
2025-04-16 09:35:18 - root - INFO - Traitement de 3 pièces jointes pour le ticket 9635
|
||||||
|
2025-04-16 09:35:18 - root - INFO - Pièce jointe téléchargée: image.png (1/3)
|
||||||
|
2025-04-16 09:35:18 - root - INFO - Pièce jointe téléchargée: image.png (2/3)
|
||||||
|
2025-04-16 09:35:18 - root - INFO - Pièce jointe téléchargée: image.png (3/3)
|
||||||
|
2025-04-16 09:35:18 - root - INFO - ------------------------------------------------------------
|
||||||
|
2025-04-16 09:35:18 - root - INFO - Extraction terminée avec succès
|
||||||
|
2025-04-16 09:35:18 - root - INFO - Ticket: T9656
|
||||||
|
2025-04-16 09:35:18 - root - INFO - Répertoire: output/ticket_T9656/T9656_20250416_093517
|
||||||
|
2025-04-16 09:35:18 - root - INFO - Messages traités: 5
|
||||||
|
2025-04-16 09:35:18 - root - INFO - Pièces jointes: 3
|
||||||
|
2025-04-16 09:35:18 - root - INFO - ------------------------------------------------------------
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user