1804-15:18
@ -1,368 +0,0 @@
|
||||
import json
|
||||
import os
|
||||
from ..base_agent import BaseAgent
|
||||
from datetime import datetime
|
||||
from typing import Dict, Any, Tuple, Optional, List
|
||||
import logging
|
||||
import traceback
|
||||
import re
|
||||
import sys
|
||||
from ..utils.report_utils import extraire_et_traiter_json
|
||||
from ..utils.report_formatter import extraire_sections_texte, generer_rapport_markdown, construire_rapport_json
|
||||
from ..utils.agent_info_collector import collecter_info_agents, collecter_prompts_agents
|
||||
|
||||
logger = logging.getLogger("AgentReportGenerator")
|
||||
|
||||
class AgentReportGenerator(BaseAgent):
|
||||
"""
|
||||
Agent pour générer un rapport synthétique à partir des analyses de ticket et d'images.
|
||||
"""
|
||||
def __init__(self, llm):
|
||||
super().__init__("AgentReportGenerator", llm)
|
||||
|
||||
# Configuration locale de l'agent
|
||||
self.temperature = 0.2
|
||||
self.top_p = 0.9
|
||||
self.max_tokens = 8000
|
||||
|
||||
# Prompt système principal
|
||||
self.system_prompt = """Tu es un expert en génération de rapports techniques pour BRG-Lab pour la société CBAO.
|
||||
Ta mission est de synthétiser les analyses (ticket et images) en un rapport structuré.
|
||||
|
||||
EXIGENCE ABSOLUE - Ton rapport DOIT inclure dans l'ordre:
|
||||
1. Un résumé du problème initial (nom de la demande + description)
|
||||
2. Une analyse détaillée des images pertinentes en lien avec le problème
|
||||
3. Une synthèse globale des analyses d'images
|
||||
4. Une reconstitution du fil de discussion client/support
|
||||
5. Un tableau JSON de chronologie des échanges avec cette structure:
|
||||
```json
|
||||
{
|
||||
"chronologie_echanges": [
|
||||
{"date": "date exacte", "emetteur": "CLIENT ou SUPPORT", "type": "Question ou Réponse", "contenu": "contenu synthétisé"}
|
||||
]
|
||||
}
|
||||
```
|
||||
6. Un diagnostic technique des causes probables
|
||||
|
||||
MÉTHODE D'ANALYSE (ÉTAPES OBLIGATOIRES):
|
||||
1. ANALYSE TOUTES les images AVANT de créer le tableau des échanges
|
||||
2. Concentre-toi sur les éléments mis en évidence (encadrés/surlignés) dans chaque image
|
||||
3. Réalise une SYNTHÈSE TRANSVERSALE en expliquant comment les images se complètent
|
||||
4. Remets les images en ordre chronologique selon le fil de discussion
|
||||
5. CONSERVE TOUS les liens documentaires, FAQ et références techniques
|
||||
6. Ajoute une entrée "Complément visuel" dans le tableau des échanges"""
|
||||
|
||||
# Version du prompt pour la traçabilité
|
||||
self.prompt_version = "v3.2"
|
||||
|
||||
# Appliquer la configuration au LLM
|
||||
self._appliquer_config_locale()
|
||||
|
||||
logger.info("AgentReportGenerator initialisé")
|
||||
|
||||
def _appliquer_config_locale(self) -> None:
|
||||
"""
|
||||
Applique la configuration locale au modèle LLM.
|
||||
"""
|
||||
# Appliquer le prompt système
|
||||
if hasattr(self.llm, "prompt_system"):
|
||||
self.llm.prompt_system = self.system_prompt
|
||||
|
||||
# Appliquer les paramètres
|
||||
if hasattr(self.llm, "configurer"):
|
||||
params = {
|
||||
"temperature": self.temperature,
|
||||
"top_p": self.top_p,
|
||||
"max_tokens": self.max_tokens
|
||||
}
|
||||
self.llm.configurer(**params)
|
||||
logger.info(f"Configuration appliquée au modèle: {str(params)}")
|
||||
|
||||
def _formater_prompt_pour_rapport(self, ticket_analyse: str, images_analyses: List[Dict]) -> str:
|
||||
"""
|
||||
Formate le prompt pour la génération du rapport
|
||||
"""
|
||||
num_images = len(images_analyses)
|
||||
logger.info(f"Formatage du prompt avec {num_images} analyses d'images")
|
||||
|
||||
# Construire la section d'analyse du ticket
|
||||
prompt = f"""Génère un rapport technique complet, en te basant sur les analyses suivantes.
|
||||
|
||||
## ANALYSE DU TICKET
|
||||
{ticket_analyse}
|
||||
"""
|
||||
|
||||
# Ajouter la section d'analyse des images si présente
|
||||
if num_images > 0:
|
||||
prompt += f"\n## ANALYSES DES IMAGES ({num_images} images)\n"
|
||||
for i, img_analyse in enumerate(images_analyses, 1):
|
||||
image_name = img_analyse.get("image_name", f"Image {i}")
|
||||
analyse = img_analyse.get("analyse", "Analyse non disponible")
|
||||
prompt += f"\n### IMAGE {i}: {image_name}\n{analyse}\n"
|
||||
else:
|
||||
prompt += "\n## ANALYSES DES IMAGES\nAucune image n'a été fournie pour ce ticket.\n"
|
||||
|
||||
# Instructions pour le rapport
|
||||
prompt += """
|
||||
## INSTRUCTIONS POUR LE RAPPORT
|
||||
|
||||
STRUCTURE OBLIGATOIRE ET ORDRE À SUIVRE:
|
||||
1. Titre principal (# Rapport d'analyse: Nom du ticket)
|
||||
2. Résumé du problème (## Résumé du problème)
|
||||
3. Analyse des images (## Analyse des images) - CRUCIAL: FAIRE CETTE SECTION AVANT LE TABLEAU
|
||||
4. Synthèse globale des analyses d'images (## 3.1 Synthèse globale des analyses d'images)
|
||||
5. Fil de discussion (## Fil de discussion)
|
||||
6. Tableau questions/réponses (## Tableau questions/réponses)
|
||||
7. Diagnostic technique (## Diagnostic technique)
|
||||
|
||||
MÉTHODE POUR ANALYSER LES IMAGES:
|
||||
- Pour chaque image, concentre-toi prioritairement sur:
|
||||
* Les éléments mis en évidence (zones encadrées, surlignées)
|
||||
* La relation avec le problème décrit
|
||||
* Le lien avec le fil de discussion
|
||||
|
||||
SYNTHÈSE GLOBALE DES IMAGES (SECTION CRUCIALE):
|
||||
- Titre à utiliser OBLIGATOIREMENT: ## 3.1 Synthèse globale des analyses d'images
|
||||
- Premier sous-titre à utiliser OBLIGATOIREMENT: _Analyse transversale des captures d'écran_
|
||||
- Structure cette section avec les sous-parties:
|
||||
* Points communs et complémentaires entre les images
|
||||
* Corrélation entre les éléments et le problème global
|
||||
* Confirmation visuelle des informations du support
|
||||
- Montre comment les images se complètent pour illustrer le processus complet
|
||||
- Cette synthèse transversale servira de base pour le "Complément visuel"
|
||||
|
||||
POUR LE TABLEAU QUESTIONS/RÉPONSES:
|
||||
- Tu DOIS créer et inclure un tableau JSON structuré comme ceci:
|
||||
```json
|
||||
{
|
||||
"chronologie_echanges": [
|
||||
{"date": "date demande", "emetteur": "CLIENT", "type": "Question", "contenu": "Texte exact du problème initial extrait du ticket"},
|
||||
{"date": "date exacte", "emetteur": "SUPPORT", "type": "Réponse", "contenu": "réponse avec TOUS les liens documentaires"},
|
||||
{"date": "date analyse", "emetteur": "SUPPORT", "type": "Complément visuel", "contenu": "synthèse unifiée de TOUTES les images"}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
DIRECTIVES ESSENTIELLES:
|
||||
- COMMENCE ABSOLUMENT par une entrée CLIENT avec les questions du NOM et de la DESCRIPTION du ticket
|
||||
- Si le premier message chronologique est une réponse du SUPPORT qui cite la question, extrais la question citée pour l'ajouter comme première entrée CLIENT
|
||||
- CONSERVE ABSOLUMENT TOUS les liens vers la documentation, FAQ, manuels et références techniques
|
||||
- Ajoute UNE SEULE entrée "Complément visuel" qui synthétise l'apport global des images
|
||||
- Cette entrée doit montrer comment les images confirment/illustrent le processus complet
|
||||
- Formulation recommandée: "L'analyse des captures d'écran confirme visuellement le processus: (1)..., (2)..., (3)... Ces interfaces complémentaires illustrent..."
|
||||
- Évite de traiter les images séparément dans le tableau; présente une vision unifiée
|
||||
- Identifie clairement chaque intervenant (CLIENT ou SUPPORT)
|
||||
"""
|
||||
|
||||
return prompt
|
||||
|
||||
def executer(self, rapport_data: Dict, rapport_dir: str) -> Tuple[Optional[str], Optional[str]]:
|
||||
"""
|
||||
Génère un rapport à partir des analyses effectuées
|
||||
"""
|
||||
try:
|
||||
# 1. PRÉPARATION
|
||||
ticket_id = self._extraire_ticket_id(rapport_data, rapport_dir)
|
||||
logger.info(f"Génération du rapport pour le ticket: {ticket_id}")
|
||||
print(f"AgentReportGenerator: Génération du rapport pour {ticket_id}")
|
||||
|
||||
# Créer le répertoire de sortie si nécessaire
|
||||
os.makedirs(rapport_dir, exist_ok=True)
|
||||
|
||||
# 2. EXTRACTION DES DONNÉES
|
||||
ticket_analyse = self._extraire_analyse_ticket(rapport_data)
|
||||
images_analyses = self._extraire_analyses_images(rapport_data)
|
||||
|
||||
# 3. COLLECTE DES INFORMATIONS SUR LES AGENTS (via le nouveau module)
|
||||
agent_info = {
|
||||
"model": getattr(self.llm, "modele", str(type(self.llm))),
|
||||
"temperature": self.temperature,
|
||||
"top_p": self.top_p,
|
||||
"max_tokens": self.max_tokens,
|
||||
"prompt_version": self.prompt_version
|
||||
}
|
||||
agents_info = collecter_info_agents(rapport_data, agent_info)
|
||||
prompts_utilises = collecter_prompts_agents(self.system_prompt)
|
||||
|
||||
# 4. GÉNÉRATION DU RAPPORT
|
||||
prompt = self._formater_prompt_pour_rapport(ticket_analyse, images_analyses)
|
||||
|
||||
logger.info("Génération du rapport avec le LLM")
|
||||
print(f" Génération du rapport avec le LLM...")
|
||||
|
||||
# Mesurer le temps d'exécution
|
||||
start_time = datetime.now()
|
||||
rapport_genere = self.llm.interroger(prompt)
|
||||
generation_time = (datetime.now() - start_time).total_seconds()
|
||||
|
||||
logger.info(f"Rapport généré: {len(rapport_genere)} caractères")
|
||||
print(f" Rapport généré: {len(rapport_genere)} caractères")
|
||||
|
||||
# 5. EXTRACTION DES DONNÉES DU RAPPORT
|
||||
# Utiliser l'utilitaire de report_utils.py pour extraire les données JSON
|
||||
rapport_traite, echanges_json, _ = extraire_et_traiter_json(rapport_genere)
|
||||
|
||||
# Vérifier que echanges_json n'est pas None pour éviter l'erreur de type
|
||||
if echanges_json is None:
|
||||
echanges_json = {"chronologie_echanges": []}
|
||||
logger.warning("Aucun échange JSON extrait du rapport, création d'une structure vide")
|
||||
|
||||
# Extraire les sections textuelles (résumé, diagnostic)
|
||||
resume, analyse_images, diagnostic = extraire_sections_texte(rapport_genere)
|
||||
|
||||
# 6. CRÉATION DU RAPPORT JSON
|
||||
# Préparer les métadonnées de l'agent
|
||||
agent_metadata = {
|
||||
"model": getattr(self.llm, "modele", str(type(self.llm))),
|
||||
"model_version": getattr(self.llm, "version", "non spécifiée"),
|
||||
"temperature": self.temperature,
|
||||
"top_p": self.top_p,
|
||||
"max_tokens": self.max_tokens,
|
||||
"generation_time": generation_time,
|
||||
"timestamp": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
|
||||
"agents": agents_info
|
||||
}
|
||||
|
||||
# Construire le rapport JSON
|
||||
rapport_json = construire_rapport_json(
|
||||
rapport_genere=rapport_genere,
|
||||
rapport_data=rapport_data,
|
||||
ticket_id=ticket_id,
|
||||
ticket_analyse=ticket_analyse,
|
||||
images_analyses=images_analyses,
|
||||
generation_time=generation_time,
|
||||
resume=resume,
|
||||
analyse_images=analyse_images,
|
||||
diagnostic=diagnostic,
|
||||
echanges_json=echanges_json,
|
||||
agent_metadata=agent_metadata,
|
||||
prompts_utilises=prompts_utilises
|
||||
)
|
||||
|
||||
# 7. SAUVEGARDE DU RAPPORT JSON
|
||||
json_path = os.path.join(rapport_dir, f"{ticket_id}_rapport_final.json")
|
||||
|
||||
with open(json_path, "w", encoding="utf-8") as f:
|
||||
json.dump(rapport_json, f, ensure_ascii=False, indent=2)
|
||||
|
||||
logger.info(f"Rapport JSON sauvegardé: {json_path}")
|
||||
print(f" Rapport JSON sauvegardé: {json_path}")
|
||||
|
||||
# 8. GÉNÉRATION DU RAPPORT MARKDOWN
|
||||
md_path = generer_rapport_markdown(json_path)
|
||||
|
||||
if md_path:
|
||||
logger.info(f"Rapport Markdown généré: {md_path}")
|
||||
print(f" Rapport Markdown généré: {md_path}")
|
||||
else:
|
||||
logger.error("Échec de la génération du rapport Markdown")
|
||||
print(f" ERREUR: Échec de la génération du rapport Markdown")
|
||||
|
||||
return json_path, md_path
|
||||
|
||||
except Exception as e:
|
||||
error_message = f"Erreur lors de la génération du rapport: {str(e)}"
|
||||
logger.error(error_message)
|
||||
logger.error(traceback.format_exc())
|
||||
print(f" ERREUR: {error_message}")
|
||||
return None, None
|
||||
|
||||
def _extraire_ticket_id(self, rapport_data: Dict, rapport_dir: str) -> str:
|
||||
"""Extrait l'ID du ticket des données ou du chemin"""
|
||||
# Essayer d'extraire depuis les données du rapport
|
||||
ticket_id = rapport_data.get("ticket_id", "")
|
||||
|
||||
# Si pas d'ID direct, essayer depuis les données du ticket
|
||||
if not ticket_id and "ticket_data" in rapport_data and isinstance(rapport_data["ticket_data"], dict):
|
||||
ticket_id = rapport_data["ticket_data"].get("code", "")
|
||||
|
||||
# En dernier recours, extraire depuis le chemin
|
||||
if not ticket_id:
|
||||
# Essayer d'extraire un ID de ticket (format Txxxx) du chemin
|
||||
match = re.search(r'T\d+', rapport_dir)
|
||||
if match:
|
||||
ticket_id = match.group(0)
|
||||
else:
|
||||
# Sinon, utiliser le dernier segment du chemin
|
||||
ticket_id = os.path.basename(rapport_dir)
|
||||
|
||||
return ticket_id
|
||||
|
||||
def _extraire_analyse_ticket(self, rapport_data: Dict) -> str:
|
||||
"""Extrait l'analyse du ticket des données"""
|
||||
# Essayer les différentes clés possibles
|
||||
for key in ["ticket_analyse", "analyse_json", "analyse_ticket"]:
|
||||
if key in rapport_data and rapport_data[key]:
|
||||
logger.info(f"Utilisation de {key}")
|
||||
return rapport_data[key]
|
||||
|
||||
# Créer une analyse par défaut si aucune n'est disponible
|
||||
logger.warning("Aucune analyse de ticket disponible, création d'un message par défaut")
|
||||
ticket_data = rapport_data.get("ticket_data", {})
|
||||
ticket_name = ticket_data.get("name", "Sans titre")
|
||||
ticket_desc = ticket_data.get("description", "Pas de description disponible")
|
||||
return f"Analyse par défaut du ticket:\nNom: {ticket_name}\nDescription: {ticket_desc}\n(Aucune analyse détaillée n'a été fournie)"
|
||||
|
||||
def _extraire_analyses_images(self, rapport_data: Dict) -> List[Dict]:
|
||||
"""
|
||||
Extrait et formate les analyses d'images pertinentes
|
||||
"""
|
||||
images_analyses = []
|
||||
analyse_images_data = rapport_data.get("analyse_images", {})
|
||||
|
||||
# Parcourir toutes les images
|
||||
for image_path, analyse_data in analyse_images_data.items():
|
||||
# Vérifier si l'image est pertinente
|
||||
is_relevant = False
|
||||
if "sorting" in analyse_data and isinstance(analyse_data["sorting"], dict):
|
||||
is_relevant = analyse_data["sorting"].get("is_relevant", False)
|
||||
|
||||
# Si l'image est pertinente, extraire son analyse
|
||||
if is_relevant:
|
||||
image_name = os.path.basename(image_path)
|
||||
analyse = self._extraire_analyse_image(analyse_data)
|
||||
|
||||
if analyse:
|
||||
images_analyses.append({
|
||||
"image_name": image_name,
|
||||
"image_path": image_path,
|
||||
"analyse": analyse,
|
||||
"sorting_info": analyse_data.get("sorting", {}),
|
||||
"metadata": analyse_data.get("analysis", {}).get("metadata", {})
|
||||
})
|
||||
logger.info(f"Analyse de l'image {image_name} ajoutée")
|
||||
|
||||
return images_analyses
|
||||
|
||||
def _extraire_analyse_image(self, analyse_data: Dict) -> Optional[str]:
|
||||
"""
|
||||
Extrait l'analyse d'une image depuis les données
|
||||
"""
|
||||
# Si pas de données d'analyse, retourner None
|
||||
if not "analysis" in analyse_data or not analyse_data["analysis"]:
|
||||
if "sorting" in analyse_data and isinstance(analyse_data["sorting"], dict):
|
||||
reason = analyse_data["sorting"].get("reason", "Non spécifiée")
|
||||
return f"Image marquée comme pertinente. Raison: {reason}"
|
||||
return None
|
||||
|
||||
# Extraire l'analyse selon le format des données
|
||||
analysis = analyse_data["analysis"]
|
||||
|
||||
# Structure type 1: {"analyse": "texte"}
|
||||
if isinstance(analysis, dict) and "analyse" in analysis:
|
||||
return analysis["analyse"]
|
||||
|
||||
# Structure type 2: {"error": false, ...} - contient d'autres données utiles
|
||||
if isinstance(analysis, dict) and "error" in analysis and not analysis.get("error", True):
|
||||
return str(analysis)
|
||||
|
||||
# Structure type 3: texte d'analyse direct
|
||||
if isinstance(analysis, str):
|
||||
return analysis
|
||||
|
||||
# Structure type 4: autre format de dictionnaire - convertir en JSON
|
||||
if isinstance(analysis, dict):
|
||||
return json.dumps(analysis, ensure_ascii=False, indent=2)
|
||||
|
||||
# Aucun format reconnu
|
||||
return None
|
||||
@ -1,106 +1,368 @@
|
||||
from ..base_agent import BaseAgent
|
||||
from typing import Dict, Any
|
||||
import logging
|
||||
import json
|
||||
import os
|
||||
from ..base_agent import BaseAgent
|
||||
from datetime import datetime
|
||||
from ..utils.pipeline_logger import sauvegarder_donnees
|
||||
from typing import Dict, Any, Tuple, Optional, List
|
||||
import logging
|
||||
import traceback
|
||||
import re
|
||||
import sys
|
||||
from ..utils.report_utils import extraire_et_traiter_json
|
||||
from ..utils.report_formatter import extraire_sections_texte, generer_rapport_markdown, construire_rapport_json
|
||||
from ..utils.agent_info_collector import collecter_info_agents, collecter_prompts_agents
|
||||
|
||||
logger = logging.getLogger("AgentReportGenerator")
|
||||
|
||||
class AgentReportGenerator(BaseAgent):
|
||||
"""
|
||||
Agent pour générer un rapport synthétique à partir des analyses de ticket et d'images.
|
||||
"""
|
||||
def __init__(self, llm):
|
||||
super().__init__("AgentReportGenerator", llm)
|
||||
|
||||
# Configuration locale de l'agent
|
||||
self.temperature = 0.2
|
||||
self.top_p = 0.9
|
||||
self.max_tokens = 8000
|
||||
|
||||
# Prompt système principal
|
||||
self.system_prompt = """Tu es un expert en génération de rapports techniques pour BRG-Lab pour la société CBAO.
|
||||
Ta mission est de synthétiser les analyses (ticket et images) en un rapport structuré.
|
||||
|
||||
self.params = {
|
||||
"temperature": 0.2,
|
||||
"top_p": 0.8,
|
||||
"max_tokens": 8000
|
||||
}
|
||||
|
||||
self.system_prompt = """Tu es un expert en support technique chargé de générer un rapport final à partir des analyses d'un ticket de support.
|
||||
Ton rôle est de croiser les informations provenant :
|
||||
- de l'analyse textuelle du ticket client
|
||||
- des analyses détaillées de plusieurs captures d'écran
|
||||
|
||||
Tu dois structurer ta réponse en format question/réponse de manière claire, en gardant l'intégralité des points importants.
|
||||
|
||||
Ne propose jamais de solution. Ne reformule pas le contexte.
|
||||
Ta seule mission est de croiser les données textuelles et visuelles et d'en tirer des observations claires, en listant les éléments factuels visibles dans les captures qui appuient ou complètent le texte du ticket.
|
||||
|
||||
Structure du rapport attendu :
|
||||
1. Contexte général (résumé du ticket textuel en une phrase)
|
||||
2. Problèmes ou questions identifiés (sous forme de questions claires)
|
||||
3. Résumé croisé image/texte pour chaque question
|
||||
4. Liste d'observations supplémentaires pertinentes (si applicable)
|
||||
|
||||
Reste strictement factuel. Ne fais aucune hypothèse. Ne suggère pas d'étapes ni d'interprétation."""
|
||||
EXIGENCE ABSOLUE - Ton rapport DOIT inclure dans l'ordre:
|
||||
1. Un résumé du problème initial (nom de la demande + description)
|
||||
2. Une analyse détaillée des images pertinentes en lien avec le problème
|
||||
3. Une synthèse globale des analyses d'images
|
||||
4. Une reconstitution du fil de discussion client/support
|
||||
5. Un tableau JSON de chronologie des échanges avec cette structure:
|
||||
```json
|
||||
{
|
||||
"chronologie_echanges": [
|
||||
{"date": "date exacte", "emetteur": "CLIENT ou SUPPORT", "type": "Question ou Réponse", "contenu": "contenu synthétisé"}
|
||||
]
|
||||
}
|
||||
```
|
||||
6. Un diagnostic technique des causes probables
|
||||
|
||||
MÉTHODE D'ANALYSE (ÉTAPES OBLIGATOIRES):
|
||||
1. ANALYSE TOUTES les images AVANT de créer le tableau des échanges
|
||||
2. Concentre-toi sur les éléments mis en évidence (encadrés/surlignés) dans chaque image
|
||||
3. Réalise une SYNTHÈSE TRANSVERSALE en expliquant comment les images se complètent
|
||||
4. Remets les images en ordre chronologique selon le fil de discussion
|
||||
5. CONSERVE TOUS les liens documentaires, FAQ et références techniques
|
||||
6. Ajoute une entrée "Complément visuel" dans le tableau des échanges"""
|
||||
|
||||
# Version du prompt pour la traçabilité
|
||||
self.prompt_version = "v3.2"
|
||||
|
||||
# Appliquer la configuration au LLM
|
||||
self._appliquer_config_locale()
|
||||
|
||||
logger.info("AgentReportGenerator initialisé")
|
||||
|
||||
|
||||
def _appliquer_config_locale(self) -> None:
|
||||
"""
|
||||
Applique la configuration locale au modèle LLM.
|
||||
"""
|
||||
# Appliquer le prompt système
|
||||
if hasattr(self.llm, "prompt_system"):
|
||||
self.llm.prompt_system = self.system_prompt
|
||||
|
||||
# Appliquer les paramètres
|
||||
if hasattr(self.llm, "configurer"):
|
||||
self.llm.configurer(**self.params)
|
||||
|
||||
def executer(self, rapport_data: Dict[str, Any], dossier_destination: str) -> str:
|
||||
ticket_id = rapport_data.get("ticket_id", "Inconnu")
|
||||
print(f"AgentReportGenerator : génération du rapport pour le ticket {ticket_id}")
|
||||
|
||||
try:
|
||||
prompt = self._generer_prompt(rapport_data)
|
||||
response = self.llm.interroger(prompt)
|
||||
|
||||
logger.info(f"Rapport généré pour le ticket {ticket_id}, longueur: {len(response)} caractères")
|
||||
|
||||
result = {
|
||||
"prompt": prompt,
|
||||
"response": response,
|
||||
"metadata": {
|
||||
"ticket_id": ticket_id,
|
||||
"timestamp": self._get_timestamp(),
|
||||
"source_agent": self.nom,
|
||||
"model_info": {
|
||||
"model": getattr(self.llm, "modele", str(type(self.llm))),
|
||||
**getattr(self.llm, "params", {})
|
||||
}
|
||||
}
|
||||
params = {
|
||||
"temperature": self.temperature,
|
||||
"top_p": self.top_p,
|
||||
"max_tokens": self.max_tokens
|
||||
}
|
||||
self.llm.configurer(**params)
|
||||
logger.info(f"Configuration appliquée au modèle: {str(params)}")
|
||||
|
||||
def _formater_prompt_pour_rapport(self, ticket_analyse: str, images_analyses: List[Dict]) -> str:
|
||||
"""
|
||||
Formate le prompt pour la génération du rapport
|
||||
"""
|
||||
num_images = len(images_analyses)
|
||||
logger.info(f"Formatage du prompt avec {num_images} analyses d'images")
|
||||
|
||||
# Construire la section d'analyse du ticket
|
||||
prompt = f"""Génère un rapport technique complet, en te basant sur les analyses suivantes.
|
||||
|
||||
sauvegarder_donnees(ticket_id, "rapport_final", result, base_dir=dossier_destination, is_resultat=True)
|
||||
## ANALYSE DU TICKET
|
||||
{ticket_analyse}
|
||||
"""
|
||||
|
||||
# Ajouter la section d'analyse des images si présente
|
||||
if num_images > 0:
|
||||
prompt += f"\n## ANALYSES DES IMAGES ({num_images} images)\n"
|
||||
for i, img_analyse in enumerate(images_analyses, 1):
|
||||
image_name = img_analyse.get("image_name", f"Image {i}")
|
||||
analyse = img_analyse.get("analyse", "Analyse non disponible")
|
||||
prompt += f"\n### IMAGE {i}: {image_name}\n{analyse}\n"
|
||||
else:
|
||||
prompt += "\n## ANALYSES DES IMAGES\nAucune image n'a été fournie pour ce ticket.\n"
|
||||
|
||||
# Instructions pour le rapport
|
||||
prompt += """
|
||||
## INSTRUCTIONS POUR LE RAPPORT
|
||||
|
||||
self.ajouter_historique("rapport_final", {
|
||||
"ticket_id": ticket_id,
|
||||
"prompt": prompt,
|
||||
"timestamp": self._get_timestamp()
|
||||
}, response)
|
||||
STRUCTURE OBLIGATOIRE ET ORDRE À SUIVRE:
|
||||
1. Titre principal (# Rapport d'analyse: Nom du ticket)
|
||||
2. Résumé du problème (## Résumé du problème)
|
||||
3. Analyse des images (## Analyse des images) - CRUCIAL: FAIRE CETTE SECTION AVANT LE TABLEAU
|
||||
4. Synthèse globale des analyses d'images (## 3.1 Synthèse globale des analyses d'images)
|
||||
5. Fil de discussion (## Fil de discussion)
|
||||
6. Tableau questions/réponses (## Tableau questions/réponses)
|
||||
7. Diagnostic technique (## Diagnostic technique)
|
||||
|
||||
return response
|
||||
MÉTHODE POUR ANALYSER LES IMAGES:
|
||||
- Pour chaque image, concentre-toi prioritairement sur:
|
||||
* Les éléments mis en évidence (zones encadrées, surlignées)
|
||||
* La relation avec le problème décrit
|
||||
* Le lien avec le fil de discussion
|
||||
|
||||
SYNTHÈSE GLOBALE DES IMAGES (SECTION CRUCIALE):
|
||||
- Titre à utiliser OBLIGATOIREMENT: ## 3.1 Synthèse globale des analyses d'images
|
||||
- Premier sous-titre à utiliser OBLIGATOIREMENT: _Analyse transversale des captures d'écran_
|
||||
- Structure cette section avec les sous-parties:
|
||||
* Points communs et complémentaires entre les images
|
||||
* Corrélation entre les éléments et le problème global
|
||||
* Confirmation visuelle des informations du support
|
||||
- Montre comment les images se complètent pour illustrer le processus complet
|
||||
- Cette synthèse transversale servira de base pour le "Complément visuel"
|
||||
|
||||
POUR LE TABLEAU QUESTIONS/RÉPONSES:
|
||||
- Tu DOIS créer et inclure un tableau JSON structuré comme ceci:
|
||||
```json
|
||||
{
|
||||
"chronologie_echanges": [
|
||||
{"date": "date demande", "emetteur": "CLIENT", "type": "Question", "contenu": "Texte exact du problème initial extrait du ticket"},
|
||||
{"date": "date exacte", "emetteur": "SUPPORT", "type": "Réponse", "contenu": "réponse avec TOUS les liens documentaires"},
|
||||
{"date": "date analyse", "emetteur": "SUPPORT", "type": "Complément visuel", "contenu": "synthèse unifiée de TOUTES les images"}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
DIRECTIVES ESSENTIELLES:
|
||||
- COMMENCE ABSOLUMENT par une entrée CLIENT avec les questions du NOM et de la DESCRIPTION du ticket
|
||||
- Si le premier message chronologique est une réponse du SUPPORT qui cite la question, extrais la question citée pour l'ajouter comme première entrée CLIENT
|
||||
- CONSERVE ABSOLUMENT TOUS les liens vers la documentation, FAQ, manuels et références techniques
|
||||
- Ajoute UNE SEULE entrée "Complément visuel" qui synthétise l'apport global des images
|
||||
- Cette entrée doit montrer comment les images confirment/illustrent le processus complet
|
||||
- Formulation recommandée: "L'analyse des captures d'écran confirme visuellement le processus: (1)..., (2)..., (3)... Ces interfaces complémentaires illustrent..."
|
||||
- Évite de traiter les images séparément dans le tableau; présente une vision unifiée
|
||||
- Identifie clairement chaque intervenant (CLIENT ou SUPPORT)
|
||||
"""
|
||||
|
||||
return prompt
|
||||
|
||||
def executer(self, rapport_data: Dict, rapport_dir: str) -> Tuple[Optional[str], Optional[str]]:
|
||||
"""
|
||||
Génère un rapport à partir des analyses effectuées
|
||||
"""
|
||||
try:
|
||||
# 1. PRÉPARATION
|
||||
ticket_id = self._extraire_ticket_id(rapport_data, rapport_dir)
|
||||
logger.info(f"Génération du rapport pour le ticket: {ticket_id}")
|
||||
print(f"AgentReportGenerator: Génération du rapport pour {ticket_id}")
|
||||
|
||||
# Créer le répertoire de sortie si nécessaire
|
||||
os.makedirs(rapport_dir, exist_ok=True)
|
||||
|
||||
# 2. EXTRACTION DES DONNÉES
|
||||
ticket_analyse = self._extraire_analyse_ticket(rapport_data)
|
||||
images_analyses = self._extraire_analyses_images(rapport_data)
|
||||
|
||||
# 3. COLLECTE DES INFORMATIONS SUR LES AGENTS (via le nouveau module)
|
||||
agent_info = {
|
||||
"model": getattr(self.llm, "modele", str(type(self.llm))),
|
||||
"temperature": self.temperature,
|
||||
"top_p": self.top_p,
|
||||
"max_tokens": self.max_tokens,
|
||||
"prompt_version": self.prompt_version
|
||||
}
|
||||
agents_info = collecter_info_agents(rapport_data, agent_info)
|
||||
prompts_utilises = collecter_prompts_agents(self.system_prompt)
|
||||
|
||||
# 4. GÉNÉRATION DU RAPPORT
|
||||
prompt = self._formater_prompt_pour_rapport(ticket_analyse, images_analyses)
|
||||
|
||||
logger.info("Génération du rapport avec le LLM")
|
||||
print(f" Génération du rapport avec le LLM...")
|
||||
|
||||
# Mesurer le temps d'exécution
|
||||
start_time = datetime.now()
|
||||
rapport_genere = self.llm.interroger(prompt)
|
||||
generation_time = (datetime.now() - start_time).total_seconds()
|
||||
|
||||
logger.info(f"Rapport généré: {len(rapport_genere)} caractères")
|
||||
print(f" Rapport généré: {len(rapport_genere)} caractères")
|
||||
|
||||
# 5. EXTRACTION DES DONNÉES DU RAPPORT
|
||||
# Utiliser l'utilitaire de report_utils.py pour extraire les données JSON
|
||||
rapport_traite, echanges_json, _ = extraire_et_traiter_json(rapport_genere)
|
||||
|
||||
# Vérifier que echanges_json n'est pas None pour éviter l'erreur de type
|
||||
if echanges_json is None:
|
||||
echanges_json = {"chronologie_echanges": []}
|
||||
logger.warning("Aucun échange JSON extrait du rapport, création d'une structure vide")
|
||||
|
||||
# Extraire les sections textuelles (résumé, diagnostic)
|
||||
resume, analyse_images, diagnostic = extraire_sections_texte(rapport_genere)
|
||||
|
||||
# 6. CRÉATION DU RAPPORT JSON
|
||||
# Préparer les métadonnées de l'agent
|
||||
agent_metadata = {
|
||||
"model": getattr(self.llm, "modele", str(type(self.llm))),
|
||||
"model_version": getattr(self.llm, "version", "non spécifiée"),
|
||||
"temperature": self.temperature,
|
||||
"top_p": self.top_p,
|
||||
"max_tokens": self.max_tokens,
|
||||
"generation_time": generation_time,
|
||||
"timestamp": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
|
||||
"agents": agents_info
|
||||
}
|
||||
|
||||
# Construire le rapport JSON
|
||||
rapport_json = construire_rapport_json(
|
||||
rapport_genere=rapport_genere,
|
||||
rapport_data=rapport_data,
|
||||
ticket_id=ticket_id,
|
||||
ticket_analyse=ticket_analyse,
|
||||
images_analyses=images_analyses,
|
||||
generation_time=generation_time,
|
||||
resume=resume,
|
||||
analyse_images=analyse_images,
|
||||
diagnostic=diagnostic,
|
||||
echanges_json=echanges_json,
|
||||
agent_metadata=agent_metadata,
|
||||
prompts_utilises=prompts_utilises
|
||||
)
|
||||
|
||||
# 7. SAUVEGARDE DU RAPPORT JSON
|
||||
json_path = os.path.join(rapport_dir, f"{ticket_id}_rapport_final.json")
|
||||
|
||||
with open(json_path, "w", encoding="utf-8") as f:
|
||||
json.dump(rapport_json, f, ensure_ascii=False, indent=2)
|
||||
|
||||
logger.info(f"Rapport JSON sauvegardé: {json_path}")
|
||||
print(f" Rapport JSON sauvegardé: {json_path}")
|
||||
|
||||
# 8. GÉNÉRATION DU RAPPORT MARKDOWN
|
||||
md_path = generer_rapport_markdown(json_path)
|
||||
|
||||
if md_path:
|
||||
logger.info(f"Rapport Markdown généré: {md_path}")
|
||||
print(f" Rapport Markdown généré: {md_path}")
|
||||
else:
|
||||
logger.error("Échec de la génération du rapport Markdown")
|
||||
print(f" ERREUR: Échec de la génération du rapport Markdown")
|
||||
|
||||
return json_path, md_path
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Erreur lors de la génération du rapport : {str(e)}")
|
||||
return f"ERREUR: {str(e)}"
|
||||
|
||||
def _generer_prompt(self, rapport_data: Dict[str, Any]) -> str:
|
||||
ticket_text = rapport_data.get("ticket_analyse", "")
|
||||
image_blocs = []
|
||||
analyses_images = rapport_data.get("analyse_images", {})
|
||||
|
||||
for chemin_image, analyse_obj in analyses_images.items():
|
||||
analyse = analyse_obj.get("analysis", {}).get("analyse", "")
|
||||
if analyse:
|
||||
image_blocs.append(f"--- IMAGE : {os.path.basename(chemin_image)} ---\n{analyse}\n")
|
||||
|
||||
bloc_images = "\n".join(image_blocs)
|
||||
|
||||
return (
|
||||
f"Voici les données d'analyse pour un ticket de support :\n\n"
|
||||
f"=== ANALYSE DU TICKET ===\n{ticket_text}\n\n"
|
||||
f"=== ANALYSES D'IMAGES ===\n{bloc_images}\n\n"
|
||||
f"Génère un rapport croisé en suivant les instructions précédentes."
|
||||
)
|
||||
|
||||
def _get_timestamp(self) -> str:
|
||||
from datetime import datetime
|
||||
return datetime.now().strftime("%Y%m%d_%H%M%S")
|
||||
error_message = f"Erreur lors de la génération du rapport: {str(e)}"
|
||||
logger.error(error_message)
|
||||
logger.error(traceback.format_exc())
|
||||
print(f" ERREUR: {error_message}")
|
||||
return None, None
|
||||
|
||||
def _extraire_ticket_id(self, rapport_data: Dict, rapport_dir: str) -> str:
|
||||
"""Extrait l'ID du ticket des données ou du chemin"""
|
||||
# Essayer d'extraire depuis les données du rapport
|
||||
ticket_id = rapport_data.get("ticket_id", "")
|
||||
|
||||
# Si pas d'ID direct, essayer depuis les données du ticket
|
||||
if not ticket_id and "ticket_data" in rapport_data and isinstance(rapport_data["ticket_data"], dict):
|
||||
ticket_id = rapport_data["ticket_data"].get("code", "")
|
||||
|
||||
# En dernier recours, extraire depuis le chemin
|
||||
if not ticket_id:
|
||||
# Essayer d'extraire un ID de ticket (format Txxxx) du chemin
|
||||
match = re.search(r'T\d+', rapport_dir)
|
||||
if match:
|
||||
ticket_id = match.group(0)
|
||||
else:
|
||||
# Sinon, utiliser le dernier segment du chemin
|
||||
ticket_id = os.path.basename(rapport_dir)
|
||||
|
||||
return ticket_id
|
||||
|
||||
def _extraire_analyse_ticket(self, rapport_data: Dict) -> str:
|
||||
"""Extrait l'analyse du ticket des données"""
|
||||
# Essayer les différentes clés possibles
|
||||
for key in ["ticket_analyse", "analyse_json", "analyse_ticket"]:
|
||||
if key in rapport_data and rapport_data[key]:
|
||||
logger.info(f"Utilisation de {key}")
|
||||
return rapport_data[key]
|
||||
|
||||
# Créer une analyse par défaut si aucune n'est disponible
|
||||
logger.warning("Aucune analyse de ticket disponible, création d'un message par défaut")
|
||||
ticket_data = rapport_data.get("ticket_data", {})
|
||||
ticket_name = ticket_data.get("name", "Sans titre")
|
||||
ticket_desc = ticket_data.get("description", "Pas de description disponible")
|
||||
return f"Analyse par défaut du ticket:\nNom: {ticket_name}\nDescription: {ticket_desc}\n(Aucune analyse détaillée n'a été fournie)"
|
||||
|
||||
def _extraire_analyses_images(self, rapport_data: Dict) -> List[Dict]:
|
||||
"""
|
||||
Extrait et formate les analyses d'images pertinentes
|
||||
"""
|
||||
images_analyses = []
|
||||
analyse_images_data = rapport_data.get("analyse_images", {})
|
||||
|
||||
# Parcourir toutes les images
|
||||
for image_path, analyse_data in analyse_images_data.items():
|
||||
# Vérifier si l'image est pertinente
|
||||
is_relevant = False
|
||||
if "sorting" in analyse_data and isinstance(analyse_data["sorting"], dict):
|
||||
is_relevant = analyse_data["sorting"].get("is_relevant", False)
|
||||
|
||||
# Si l'image est pertinente, extraire son analyse
|
||||
if is_relevant:
|
||||
image_name = os.path.basename(image_path)
|
||||
analyse = self._extraire_analyse_image(analyse_data)
|
||||
|
||||
if analyse:
|
||||
images_analyses.append({
|
||||
"image_name": image_name,
|
||||
"image_path": image_path,
|
||||
"analyse": analyse,
|
||||
"sorting_info": analyse_data.get("sorting", {}),
|
||||
"metadata": analyse_data.get("analysis", {}).get("metadata", {})
|
||||
})
|
||||
logger.info(f"Analyse de l'image {image_name} ajoutée")
|
||||
|
||||
return images_analyses
|
||||
|
||||
def _extraire_analyse_image(self, analyse_data: Dict) -> Optional[str]:
|
||||
"""
|
||||
Extrait l'analyse d'une image depuis les données
|
||||
"""
|
||||
# Si pas de données d'analyse, retourner None
|
||||
if not "analysis" in analyse_data or not analyse_data["analysis"]:
|
||||
if "sorting" in analyse_data and isinstance(analyse_data["sorting"], dict):
|
||||
reason = analyse_data["sorting"].get("reason", "Non spécifiée")
|
||||
return f"Image marquée comme pertinente. Raison: {reason}"
|
||||
return None
|
||||
|
||||
# Extraire l'analyse selon le format des données
|
||||
analysis = analyse_data["analysis"]
|
||||
|
||||
# Structure type 1: {"analyse": "texte"}
|
||||
if isinstance(analysis, dict) and "analyse" in analysis:
|
||||
return analysis["analyse"]
|
||||
|
||||
# Structure type 2: {"error": false, ...} - contient d'autres données utiles
|
||||
if isinstance(analysis, dict) and "error" in analysis and not analysis.get("error", True):
|
||||
return str(analysis)
|
||||
|
||||
# Structure type 3: texte d'analyse direct
|
||||
if isinstance(analysis, str):
|
||||
return analysis
|
||||
|
||||
# Structure type 4: autre format de dictionnaire - convertir en JSON
|
||||
if isinstance(analysis, dict):
|
||||
return json.dumps(analysis, ensure_ascii=False, indent=2)
|
||||
|
||||
# Aucun format reconnu
|
||||
return None
|
||||
106
agents/mistral_large/agent_reprot_generator.py
Normal file
@ -0,0 +1,106 @@
|
||||
from ..base_agent import BaseAgent
|
||||
from typing import Dict, Any
|
||||
import logging
|
||||
import os
|
||||
from datetime import datetime
|
||||
from ..utils.pipeline_logger import sauvegarder_donnees
|
||||
|
||||
logger = logging.getLogger("AgentReportGenerator")
|
||||
|
||||
class AgentReportGenerator(BaseAgent):
|
||||
def __init__(self, llm):
|
||||
super().__init__("AgentReportGenerator", llm)
|
||||
|
||||
self.params = {
|
||||
"temperature": 0.2,
|
||||
"top_p": 0.8,
|
||||
"max_tokens": 8000
|
||||
}
|
||||
|
||||
self.system_prompt = """Tu es un expert en support technique chargé de générer un rapport final à partir des analyses d'un ticket de support.
|
||||
Ton rôle est de croiser les informations provenant :
|
||||
- de l'analyse textuelle du ticket client
|
||||
- des analyses détaillées de plusieurs captures d'écran
|
||||
|
||||
Tu dois structurer ta réponse en format question/réponse de manière claire, en gardant l'intégralité des points importants.
|
||||
|
||||
Ne propose jamais de solution. Ne reformule pas le contexte.
|
||||
Ta seule mission est de croiser les données textuelles et visuelles et d'en tirer des observations claires, en listant les éléments factuels visibles dans les captures qui appuient ou complètent le texte du ticket.
|
||||
|
||||
Structure du rapport attendu :
|
||||
1. Contexte général (résumé du ticket textuel en une phrase)
|
||||
2. Problèmes ou questions identifiés (sous forme de questions claires)
|
||||
3. Résumé croisé image/texte pour chaque question
|
||||
4. Liste d'observations supplémentaires pertinentes (si applicable)
|
||||
|
||||
Reste strictement factuel. Ne fais aucune hypothèse. Ne suggère pas d'étapes ni d'interprétation."""
|
||||
|
||||
self._appliquer_config_locale()
|
||||
logger.info("AgentReportGenerator initialisé")
|
||||
|
||||
def _appliquer_config_locale(self) -> None:
|
||||
if hasattr(self.llm, "prompt_system"):
|
||||
self.llm.prompt_system = self.system_prompt
|
||||
if hasattr(self.llm, "configurer"):
|
||||
self.llm.configurer(**self.params)
|
||||
|
||||
def executer(self, rapport_data: Dict[str, Any], dossier_destination: str) -> str:
|
||||
ticket_id = rapport_data.get("ticket_id", "Inconnu")
|
||||
print(f"AgentReportGenerator : génération du rapport pour le ticket {ticket_id}")
|
||||
|
||||
try:
|
||||
prompt = self._generer_prompt(rapport_data)
|
||||
response = self.llm.interroger(prompt)
|
||||
|
||||
logger.info(f"Rapport généré pour le ticket {ticket_id}, longueur: {len(response)} caractères")
|
||||
|
||||
result = {
|
||||
"prompt": prompt,
|
||||
"response": response,
|
||||
"metadata": {
|
||||
"ticket_id": ticket_id,
|
||||
"timestamp": self._get_timestamp(),
|
||||
"source_agent": self.nom,
|
||||
"model_info": {
|
||||
"model": getattr(self.llm, "modele", str(type(self.llm))),
|
||||
**getattr(self.llm, "params", {})
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
sauvegarder_donnees(ticket_id, "rapport_final", result, base_dir=dossier_destination, is_resultat=True)
|
||||
|
||||
self.ajouter_historique("rapport_final", {
|
||||
"ticket_id": ticket_id,
|
||||
"prompt": prompt,
|
||||
"timestamp": self._get_timestamp()
|
||||
}, response)
|
||||
|
||||
return response
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Erreur lors de la génération du rapport : {str(e)}")
|
||||
return f"ERREUR: {str(e)}"
|
||||
|
||||
def _generer_prompt(self, rapport_data: Dict[str, Any]) -> str:
|
||||
ticket_text = rapport_data.get("ticket_analyse", "")
|
||||
image_blocs = []
|
||||
analyses_images = rapport_data.get("analyse_images", {})
|
||||
|
||||
for chemin_image, analyse_obj in analyses_images.items():
|
||||
analyse = analyse_obj.get("analysis", {}).get("analyse", "")
|
||||
if analyse:
|
||||
image_blocs.append(f"--- IMAGE : {os.path.basename(chemin_image)} ---\n{analyse}\n")
|
||||
|
||||
bloc_images = "\n".join(image_blocs)
|
||||
|
||||
return (
|
||||
f"Voici les données d'analyse pour un ticket de support :\n\n"
|
||||
f"=== ANALYSE DU TICKET ===\n{ticket_text}\n\n"
|
||||
f"=== ANALYSES D'IMAGES ===\n{bloc_images}\n\n"
|
||||
f"Génère un rapport croisé en suivant les instructions précédentes."
|
||||
)
|
||||
|
||||
def _get_timestamp(self) -> str:
|
||||
from datetime import datetime
|
||||
return datetime.now().strftime("%Y%m%d_%H%M%S")
|
||||
@ -136,7 +136,8 @@ def detect_duplicate_content(messages: List[Dict[str, Any]]) -> List[int]:
|
||||
from formatters.clean_html import clean_html
|
||||
except ImportError:
|
||||
# Fallback to a simplified version if the import fails
|
||||
def clean_html(html_content, is_description=False, strategy="standard", preserve_links=False, preserve_images=False):
|
||||
def clean_html(html_content, is_forwarded=False, is_description=False, strategy="standard",
|
||||
preserve_links=False, preserve_images=False, preserve_doc_links=True):
|
||||
return html_content.strip() if html_content else ""
|
||||
|
||||
content_map = {}
|
||||
|
||||
81
docs/core_module.md
Normal file
@ -0,0 +1,81 @@
|
||||
# Module Core
|
||||
|
||||
## Description générale
|
||||
|
||||
Le module `core` contient les fonctionnalités centrales et utilitaires communs utilisés dans l'ensemble du système d'analyse de tickets. Il fournit des outils essentiels pour la gestion des fichiers, la journalisation, et le traitement des données.
|
||||
|
||||
## Structure
|
||||
|
||||
- `core/utils.py` : Fonctions utilitaires générales
|
||||
- `core/__init__.py` : Exports des fonctions principales
|
||||
- `core/tests/` : Tests unitaires pour les fonctionnalités du module
|
||||
|
||||
## Fonctionnalités principales
|
||||
|
||||
### Journalisation (`setup_logging`, `log_separator`)
|
||||
|
||||
```python
|
||||
setup_logging(level=logging.INFO, log_file=None)
|
||||
log_separator(length=60)
|
||||
```
|
||||
|
||||
Ces fonctions permettent de configurer facilement la journalisation dans l'ensemble de l'application avec un format cohérent. Elles sont utilisées dans les scripts d'extraction de tickets et les modules d'interaction avec Odoo.
|
||||
|
||||
### Gestion de fichiers (`save_json`, `save_text`, `ensure_dir`)
|
||||
|
||||
```python
|
||||
save_json(data, file_path)
|
||||
save_text(text, file_path)
|
||||
ensure_dir(path)
|
||||
```
|
||||
|
||||
Fonctions utilisées pour sauvegarder des données au format JSON ou texte, et pour s'assurer que les répertoires existent avant d'y écrire des fichiers.
|
||||
|
||||
### Normalisation (`normalize_filename`)
|
||||
|
||||
```python
|
||||
normalize_filename(name)
|
||||
```
|
||||
|
||||
Fonction qui normalise les noms de fichiers en remplaçant les caractères non autorisés par des underscores et en limitant la longueur. Très utile pour le traitement des pièces jointes des tickets.
|
||||
|
||||
### Détection de duplicats (`detect_duplicate_content`)
|
||||
|
||||
```python
|
||||
detect_duplicate_content(messages)
|
||||
```
|
||||
|
||||
Identifie les messages avec un contenu dupliqué, ce qui permet d'éviter les redondances dans les rapports générés.
|
||||
|
||||
### Gestion du temps (`get_timestamp`)
|
||||
|
||||
```python
|
||||
get_timestamp()
|
||||
```
|
||||
|
||||
Retourne un timestamp au format standardisé (YYYYMMDD_HHMMSS) utilisé pour nommer les fichiers et tracer les opérations.
|
||||
|
||||
### Analyse d'images (`is_important_image`)
|
||||
|
||||
```python
|
||||
is_important_image(tag, message_text)
|
||||
```
|
||||
|
||||
Détermine si une image est importante ou s'il s'agit simplement d'un logo ou d'une signature dans un message.
|
||||
|
||||
## Utilisation dans le projet
|
||||
|
||||
Le module `core` est utilisé par de nombreux composants du système :
|
||||
|
||||
- Les scripts d'extraction de tickets (`odoo_extractor.py`)
|
||||
- Les modules d'interaction avec Odoo (`odoo/retrieve_ticket.py`, `odoo/message_manager.py`, etc.)
|
||||
- Potentiellement utilisable dans les nouveaux workflows de test et les agents modifiés
|
||||
|
||||
## Maintien et évolution
|
||||
|
||||
Bien que le module `core` contienne des fonctionnalités essentielles, certaines de ses fonctions pourraient être déplacées ou dupliquées dans le nouveau système de tests (`tests/common/`) pour une meilleure modularité.
|
||||
|
||||
Possibilités d'évolution :
|
||||
- Centralisation des fonctions liées aux fichiers et à la journalisation
|
||||
- Migration progressive des fonctions vers la nouvelle architecture de tests
|
||||
- Conservation des fonctions distinctes pour le traitement des tickets
|
||||
@ -28,7 +28,6 @@ python odoo_extractor.py --config config.json --verbose --output /chemin/vers/so
|
||||
- `--verbose` ou `-v`: Active le mode verbeux pour plus de détails lors de l'exécution.
|
||||
- `--output` ou `-o`: Répertoire de sortie pour les fichiers générés.
|
||||
- `--no-md`: Désactive la génération automatique du fichier Markdown.
|
||||
- `--extract-html-images`: Active l'extraction des images intégrées dans le HTML.
|
||||
|
||||
### Exemples
|
||||
|
||||
|
||||
@ -232,7 +232,8 @@ class AttachmentManager:
|
||||
|
||||
def extract_missing_images(self, messages_data: Dict[str, Any], output_dir: str) -> List[Dict[str, Any]]:
|
||||
"""
|
||||
Extrait les images manquantes qui sont intégrées dans les messages HTML mais non attachées au ticket.
|
||||
Extrait les images intégrées dans les messages HTML mais non attachées au ticket.
|
||||
Cette version ne dépend pas du module utils/image_extractor supprimé.
|
||||
|
||||
Args:
|
||||
messages_data: Données des messages du ticket
|
||||
@ -269,10 +270,10 @@ class AttachmentManager:
|
||||
if id_match:
|
||||
img_id = id_match.group(1)
|
||||
|
||||
# Vérifier si cette image existe déjà
|
||||
if img_id in existing_attachments:
|
||||
logging.info(f"Image avec ID {img_id} déjà présente dans les pièces jointes, ignorée")
|
||||
continue
|
||||
# Vérifier si cette image existe déjà
|
||||
if img_id in existing_attachments:
|
||||
logging.info(f"Image avec ID {img_id} déjà présente dans les pièces jointes, ignorée")
|
||||
continue
|
||||
|
||||
# Télécharger l'image
|
||||
result = self.download_image_from_url(url, output_dir)
|
||||
@ -304,7 +305,7 @@ class AttachmentManager:
|
||||
logging.info(f"Image téléchargée depuis l'URL: {url}")
|
||||
|
||||
logging.info(f"Total des images extraites: {len(extracted_images)}")
|
||||
|
||||
|
||||
except Exception as e:
|
||||
logging.error(f"Erreur lors de l'extraction des images manquantes: {e}")
|
||||
|
||||
@ -395,8 +396,6 @@ class AttachmentManager:
|
||||
|
||||
if not attachments:
|
||||
logging.info(f"Aucune pièce jointe trouvée pour le ticket {ticket_id}")
|
||||
# Si aucune pièce jointe trouvée mais que nous avons les messages,
|
||||
# on peut quand même chercher des images intégrées
|
||||
attachments_info = []
|
||||
else:
|
||||
logging.info(f"Traitement de {len(attachments)} pièces jointes pour le ticket {ticket_id}")
|
||||
|
||||
@ -14,14 +14,6 @@ from odoo.retrieve_ticket import retrieve_ticket
|
||||
from odoo.retrieve_tickets_batch import retrieve_tickets_batch, parse_domain, list_projects, list_stages
|
||||
from odoo.auth_manager import get_auth_manager, load_config
|
||||
|
||||
#importation de l'extracteur d'images HTML (optionnel)
|
||||
try:
|
||||
from utils.image_extractor import extract_images_from_ticket
|
||||
from utils.image_extractor.extract_all_images import enhance_ticket_data_with_images
|
||||
HTML_IMAGE_EXTRACTOR_AVAILABLE = True
|
||||
except ImportError:
|
||||
HTML_IMAGE_EXTRACTOR_AVAILABLE = False
|
||||
|
||||
def parse_arguments():
|
||||
"""Parse les arguments de ligne de commande."""
|
||||
parser = argparse.ArgumentParser(description="Extrait des données depuis Odoo (ticket unique ou par lots).")
|
||||
@ -31,7 +23,6 @@ def parse_arguments():
|
||||
parser.add_argument("--verbose", "-v", action="store_true", help="Mode verbeux")
|
||||
parser.add_argument("--output", "-o", help="Répertoire de sortie", default=None)
|
||||
parser.add_argument("--no-md", action="store_true", help="Désactiver la génération automatique du fichier Markdown")
|
||||
parser.add_argument("--extract-html-images", action="store_true", help="Activer l'extraction des images intégrées dans le HTML")
|
||||
|
||||
# Sous-parseurs pour les différentes commandes
|
||||
subparsers = parser.add_subparsers(dest="command", help="Commande à exécuter")
|
||||
|
||||
@ -1,34 +0,0 @@
|
||||
[
|
||||
{
|
||||
"analyse": "### Analyse de l'image\n\n#### 1. Description objective\nL'image montre une interface web affichée dans un navigateur. Voici les éléments visibles :\n- **Nom du logiciel ou module** : \"Apache Tomcat\" est visible dans l'onglet du navigateur.\n- **Interface logicielle** : La page affiche un message de succès avec le titre \"It works !\".\n- **Contenu de la page** :\n - Un message principal : \"If you're seeing this page via a web browser, it means you've setup Tomcat successfully. Congratulations!\"\n - Des instructions supplémentaires pour accéder à la documentation et aux exemples de Tomcat.\n - Des liens cliquables :\n - `tomcat-docs` : Accès à la documentation locale de Tomcat.\n - `tomcat-examples` : Accès aux exemples de servlets et JSP.\n - `tomcat-admin` : Accès à l'interface d'administration de Tomcat.\n - Une note de sécurité indiquant que l'accès aux interfaces `manager-gui` et `host-manager-gui` est restreint aux utilisateurs ayant les rôles appropriés.\n\n#### 2. Éléments techniques clés\n- **Version logicielle** : Aucune version spécifique de Tomcat n'est mentionnée dans l'image.\n- **Codes d'erreur visibles** : Aucun code d'erreur n'est visible.\n- **Paramètres configurables** : Aucun paramètre configurable n'est visible dans l'image.\n- **Valeurs affichées ou préremplies** : Aucune valeur n'est affichée dans des champs modifiables.\n- **Éléments désactivés, grisés ou masqués** : Aucun élément n'est désactivé, grisé ou masqué.\n- **Boutons actifs/inactifs** : Les liens `tomcat-docs`, `tomcat-examples` et `tomcat-admin` sont actifs et cliquables.\n\n#### 3. Éléments mis en évidence\n- Aucun élément n'est entouré, encadré, surligné ou fléché dans l'image.\n- Le message \"It works !\" est mis en valeur en tant que titre principal de la page.\n\n#### 4. Relation avec le problème\n- L'image montre que l'installation de Tomcat a été réalisée avec succès, comme indiqué par le message \"It works !\".\n- Il n'y a aucune mention explicite de l'essai au bleu ou d'un problème d'accès dans l'image.\n- Les liens vers la documentation, les exemples et l'interface d'administration de Tomcat sont fonctionnels, ce qui suggère que l'application est opérationnelle.\n\n#### 5. Réponses potentielles\n- L'image ne fournit pas directement de réponse à la question \"Pourquoi l'essai au bleu est-il inaccessible ?\" ou \"Comment résoudre le problème d'accès à l'essai au bleu ?\".\n- Elle confirme cependant que l'installation de Tomcat est réussie, ce qui pourrait être lié à la résolution du problème mentionné par le client.\n\n#### 6. Lien avec la discussion\n- L'image correspond à l'étape décrite dans le fil de discussion où le support demande au client de vérifier l'accès à la page `https://zk1.brg-lab.com/`.\n- Le client a confirmé que l'adresse fonctionne, ce qui est cohérent avec le contenu de l'image.\n- L'image montre que la page s'affiche correctement, sans erreur, ce qui pourrait expliquer pourquoi le client a indiqué que le problème s'est résolu de lui-même.",
|
||||
"raw_response": "### Analyse de l'image\n\n#### 1. Description objective\nL'image montre une interface web affichée dans un navigateur. Voici les éléments visibles :\n- **Nom du logiciel ou module** : \"Apache Tomcat\" est visible dans l'onglet du navigateur.\n- **Interface logicielle** : La page affiche un message de succès avec le titre \"It works !\".\n- **Contenu de la page** :\n - Un message principal : \"If you're seeing this page via a web browser, it means you've setup Tomcat successfully. Congratulations!\"\n - Des instructions supplémentaires pour accéder à la documentation et aux exemples de Tomcat.\n - Des liens cliquables :\n - `tomcat-docs` : Accès à la documentation locale de Tomcat.\n - `tomcat-examples` : Accès aux exemples de servlets et JSP.\n - `tomcat-admin` : Accès à l'interface d'administration de Tomcat.\n - Une note de sécurité indiquant que l'accès aux interfaces `manager-gui` et `host-manager-gui` est restreint aux utilisateurs ayant les rôles appropriés.\n\n#### 2. Éléments techniques clés\n- **Version logicielle** : Aucune version spécifique de Tomcat n'est mentionnée dans l'image.\n- **Codes d'erreur visibles** : Aucun code d'erreur n'est visible.\n- **Paramètres configurables** : Aucun paramètre configurable n'est visible dans l'image.\n- **Valeurs affichées ou préremplies** : Aucune valeur n'est affichée dans des champs modifiables.\n- **Éléments désactivés, grisés ou masqués** : Aucun élément n'est désactivé, grisé ou masqué.\n- **Boutons actifs/inactifs** : Les liens `tomcat-docs`, `tomcat-examples` et `tomcat-admin` sont actifs et cliquables.\n\n#### 3. Éléments mis en évidence\n- Aucun élément n'est entouré, encadré, surligné ou fléché dans l'image.\n- Le message \"It works !\" est mis en valeur en tant que titre principal de la page.\n\n#### 4. Relation avec le problème\n- L'image montre que l'installation de Tomcat a été réalisée avec succès, comme indiqué par le message \"It works !\".\n- Il n'y a aucune mention explicite de l'essai au bleu ou d'un problème d'accès dans l'image.\n- Les liens vers la documentation, les exemples et l'interface d'administration de Tomcat sont fonctionnels, ce qui suggère que l'application est opérationnelle.\n\n#### 5. Réponses potentielles\n- L'image ne fournit pas directement de réponse à la question \"Pourquoi l'essai au bleu est-il inaccessible ?\" ou \"Comment résoudre le problème d'accès à l'essai au bleu ?\".\n- Elle confirme cependant que l'installation de Tomcat est réussie, ce qui pourrait être lié à la résolution du problème mentionné par le client.\n\n#### 6. Lien avec la discussion\n- L'image correspond à l'étape décrite dans le fil de discussion où le support demande au client de vérifier l'accès à la page `https://zk1.brg-lab.com/`.\n- Le client a confirmé que l'adresse fonctionne, ce qui est cohérent avec le contenu de l'image.\n- L'image montre que la page s'affiche correctement, sans erreur, ce qui pourrait expliquer pourquoi le client a indiqué que le problème s'est résolu de lui-même.",
|
||||
"metadata": {
|
||||
"image_path": "output/ticket_T11143/T11143_20250416_103302/attachments/image.png",
|
||||
"image_name": "image.png",
|
||||
"timestamp": "20250418_115612",
|
||||
"model_info": {
|
||||
"model": "pixtral-large-latest",
|
||||
"temperature": 0.2,
|
||||
"top_p": 0.9,
|
||||
"max_tokens": 3000
|
||||
},
|
||||
"source_agent": "AgentImageAnalyser"
|
||||
}
|
||||
},
|
||||
{
|
||||
"analyse": "### Analyse de l'image\n\n#### 1. Description objective\nL'image montre une interface logicielle du module **BRG-LAB**. Voici les éléments visibles :\n- **Titre de la page** : \"Essai au bleu de méthylène (MB) - NF EN 933-9 (02-2022)\"\n- **Menu principal** : Situé à gauche, avec les sections suivantes :\n - \"ESSAIS\" (sélectionné, en surbrillance rouge)\n - \"MATÉRIAUX\"\n - \"PORTEFEUILLE\"\n - \"OBSERVATIONS\"\n - \"SMO\"\n - \"HISTORIQUE\"\n- **Sous-menu** : Sous \"ESSAIS\", les options \"FAZ\" et \"ESSAIS\" sont visibles.\n- **Informations supplémentaires** :\n - Numéro d'échantillon : 25-00075\n - Date de réception : 02/04/2025\n - Préleveur : BOLLEE Victor\n - Date de prélèvement : 02/04/2025\n - Matériau : Sable 0/2 - CARRIERE ADCEG\n- **Barre d'outils** : En haut à gauche, avec les options \"BRGLAB\", \"Briton\", \"Fournisseur Labo\", et une icône de \"Masa\".\n- **URL visible** : `https://zk1.brg-lab.com/BRG-LAB/PAGE_programme/essai/CFAAHVNCDAA`\n- **Message en bas de page** : \"Impossible de trouver l'adresse IP du serveur de zk1.brg-lab.com\"\n\n#### 2. Éléments techniques clés\n- **Modules ou versions logicielles** : Le module \"BRG-LAB\" est visible, mais aucune version spécifique n'est mentionnée.\n- **Codes d'erreur visibles** : Aucun code d'erreur n'est affiché.\n- **Paramètres configurables** :\n - Aucun champ de texte, slider, dropdown ou case à cocher n'est visible dans cette capture.\n- **Valeurs affichées ou préremplies** :\n - Les informations sur l'échantillon (numéro, date, préleveur, matériau) sont préremplies.\n- **Éléments désactivés, grisés ou masqués** :\n - Aucun élément n'est visiblement grisé ou désactivé.\n- **Boutons actifs/inactifs** :\n - Aucun bouton n'est visible dans cette capture.\n\n#### 3. Éléments mis en évidence\n- **Zones entourées, encadrées, surlignées ou fléchées** :\n - L'onglet \"ESSAIS\" est surligné en rouge dans le menu principal.\n - Aucun autre élément n'est mis en évidence.\n\n#### 4. Relation avec le problème\n- L'image montre l'accès à la page de l'essai au bleu de méthylène, ce qui est directement lié au problème décrit dans le ticket (accès à l'essai au bleu).\n- Le message en bas de page (\"Impossible de trouver l'adresse IP du serveur de",
|
||||
"raw_response": "### Analyse de l'image\n\n#### 1. Description objective\nL'image montre une interface logicielle du module **BRG-LAB**. Voici les éléments visibles :\n- **Titre de la page** : \"Essai au bleu de méthylène (MB) - NF EN 933-9 (02-2022)\"\n- **Menu principal** : Situé à gauche, avec les sections suivantes :\n - \"ESSAIS\" (sélectionné, en surbrillance rouge)\n - \"MATÉRIAUX\"\n - \"PORTEFEUILLE\"\n - \"OBSERVATIONS\"\n - \"SMO\"\n - \"HISTORIQUE\"\n- **Sous-menu** : Sous \"ESSAIS\", les options \"FAZ\" et \"ESSAIS\" sont visibles.\n- **Informations supplémentaires** :\n - Numéro d'échantillon : 25-00075\n - Date de réception : 02/04/2025\n - Préleveur : BOLLEE Victor\n - Date de prélèvement : 02/04/2025\n - Matériau : Sable 0/2 - CARRIERE ADCEG\n- **Barre d'outils** : En haut à gauche, avec les options \"BRGLAB\", \"Briton\", \"Fournisseur Labo\", et une icône de \"Masa\".\n- **URL visible** : `https://zk1.brg-lab.com/BRG-LAB/PAGE_programme/essai/CFAAHVNCDAA`\n- **Message en bas de page** : \"Impossible de trouver l'adresse IP du serveur de zk1.brg-lab.com\"\n\n#### 2. Éléments techniques clés\n- **Modules ou versions logicielles** : Le module \"BRG-LAB\" est visible, mais aucune version spécifique n'est mentionnée.\n- **Codes d'erreur visibles** : Aucun code d'erreur n'est affiché.\n- **Paramètres configurables** :\n - Aucun champ de texte, slider, dropdown ou case à cocher n'est visible dans cette capture.\n- **Valeurs affichées ou préremplies** :\n - Les informations sur l'échantillon (numéro, date, préleveur, matériau) sont préremplies.\n- **Éléments désactivés, grisés ou masqués** :\n - Aucun élément n'est visiblement grisé ou désactivé.\n- **Boutons actifs/inactifs** :\n - Aucun bouton n'est visible dans cette capture.\n\n#### 3. Éléments mis en évidence\n- **Zones entourées, encadrées, surlignées ou fléchées** :\n - L'onglet \"ESSAIS\" est surligné en rouge dans le menu principal.\n - Aucun autre élément n'est mis en évidence.\n\n#### 4. Relation avec le problème\n- L'image montre l'accès à la page de l'essai au bleu de méthylène, ce qui est directement lié au problème décrit dans le ticket (accès à l'essai au bleu).\n- Le message en bas de page (\"Impossible de trouver l'adresse IP du serveur de",
|
||||
"metadata": {
|
||||
"image_path": "output/ticket_T11143/T11143_20250416_103302/attachments/image_145435.png",
|
||||
"image_name": "image_145435.png",
|
||||
"timestamp": "20250418_115645",
|
||||
"model_info": {
|
||||
"model": "pixtral-large-latest",
|
||||
"temperature": 0.2,
|
||||
"top_p": 0.9,
|
||||
"max_tokens": 3000
|
||||
},
|
||||
"source_agent": "AgentImageAnalyser"
|
||||
}
|
||||
}
|
||||
]
|
||||
@ -1,37 +0,0 @@
|
||||
[
|
||||
{
|
||||
"prompt": "### TICKET T11143\n\n--- MESSAGE INITIAL DU CLIENT ---\nAuteur : GIRAUD TP (JCG), Victor BOLLÉE, v.bollee@labojcg.fr\nDate : 03/04/2025 08:34\nContenu :\nBRGLAB - Essai inaccessible\n*Contenu non extractible*\n\n--- MESSAGE 1 ---\nAuteur : Fabien LAFAY\nDate : 03/04/2025 08:35\nType : Système\nSujet : Re: [T11143] BRGLAB - Essai inaccessible\nContenu :\nGIRAUD TP (JCG), Victor BOLLÉE\n-\nil y a 9 minutes\n;\nFabien LAFAY\n;\nRomuald GRUSON\n;\nsupport\n;\nsupport\n-\nQuentin FAIVRE\n-\nFabien LAFAY\n-\nRomuald GRUSON\nBonjour,\nJe ne parviens pas à accéder au l’essai au bleu :\nMerci par avance pour votre.\nCordialement\n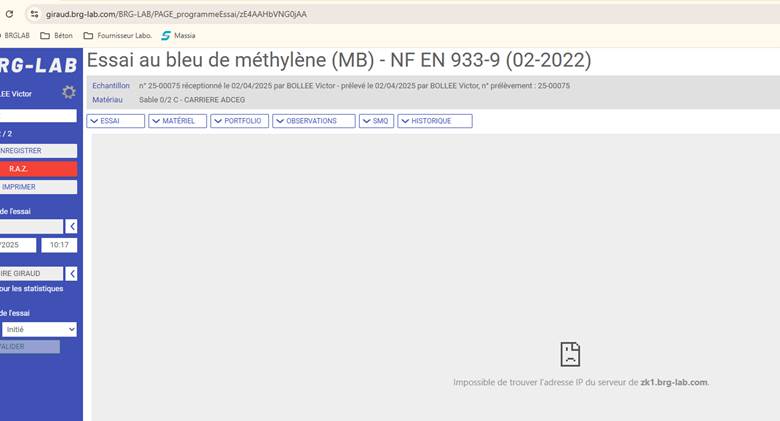\n\n---\n\n--- MESSAGE 2 ---\nAuteur : Fabien LAFAY\nDate : 03/04/2025 12:17\nType : E-mail\nSujet : Re: [T11143] - BRGLAB - Essai inaccessible\nContenu :\nBonjour\n,\nPouvez-vous vérifier si vous avez bien accès à la page suivante en l'ouvrant dans votre navigateur :\nhttps://zk1.brg-lab.com/\nVoici ce que vous devriez voir affiché :\nSi ce n'est pas le cas, pouvez-vous me faire une capture d'écran de ce qui est affiché?\nJe reste à votre entière disposition pour toute information complémentaire.\nCordialement,\n---\nSupport technique\n\n- image.png (image/png) [ID: 145453]\n\n---\n\n--- MESSAGE 3 ---\nAuteur : Victor BOLLÉE\nDate : 03/04/2025 12:21\nType : E-mail\nSujet : TR: [T11143] - BRGLAB - Essai inaccessible\nContenu :\nBonjour,\nLe problème s’est résolu seul par la suite.\nJe vous remercie pour votre retour.\nBonne journée\nPS : l’adresse fonctionne\nDe :\n\n---\n\n",
|
||||
"response": "### 1. Résumé du contexte\n\n**Client :**\n- Nom : Victor BOLLÉE\n- Email : v.bollee@labojcg.fr\n- Société : GIRAUD TP (JCG)\n- `user_id` : Non disponible\n\n**Sujet du ticket reformulé en une ou plusieurs questions :**\n- Pourquoi l'essai au bleu est-il inaccessible ?\n- Comment résoudre le problème d'accès à l'essai au bleu ?\n\n**Description technique synthétique :**\n- Le client ne parvient pas à accéder à l'essai au bleu.\n- Une capture d'écran est jointe pour illustrer le problème.\n- Le support technique demande de vérifier l'accès à une page spécifique et de fournir une capture d'écran si nécessaire.\n- Le problème s'est résolu de lui-même par la suite.\n\n### 2. Informations techniques détectées\n\n**Logiciels/modules mentionnés :**\n- BRGLAB\n\n**Paramètres évoqués :**\n- Accès à l'essai au bleu\n\n**Fonctionnalités impactées :**\n- Accès à l'essai au bleu\n\n**Conditions spécifiques :**\n- Aucune condition spécifique mentionnée\n\n### 3. Fil de discussion (filtrée, nettoyée, classée)\n\n**Intervenant : Client**\n**Date : 03/04/2025 08:34**\n**Contenu :**\nBonjour,\nJe ne parviens pas à accéder à l’essai au bleu.\nMerci par avance pour votre.\nCordialement\n\n\n**Intervenant : Support**\n**Date : 03/04/2025 12:17**\n**Contenu :**\nBonjour,\nPouvez-vous vérifier si vous avez bien accès à la page suivante en l'ouvrant dans votre navigateur :\nhttps://zk1.brg-lab.com/\nVoici ce que vous devriez voir affiché :\nSi ce n'est pas le cas, pouvez-vous me faire une capture d'écran de ce qui est affiché?\nJe reste à votre entière disposition pour toute information complémentaire.\nCordialement,\n---\nSupport technique\n- image.png (image/png) [ID: 145453]\n\n**Intervenant : Client**\n**Date : 03/04/2025 12:21**\n**Contenu :**\nBonjour,\nLe problème s’est résolu seul par la suite.\nJe vous remercie pour votre retour.\nBonne journée\nPS : l’adresse fonctionne\n\n### 4. Éléments liés à l'analyse visuelle\n\n**Nombre d'images attachées :**\n- 2 images attachées\n\n**Références aux interfaces ou options à visualiser :**\n- Accès à l'essai au bleu\n- Page https://zk1.brg-lab.com/\n\n**Points à vérifier dans les captures :**\n- Vérifier l'accès à l'essai au bleu\n- Vérifier l'affichage de la page https://zk1.brg-lab.com/",
|
||||
"metadata": {
|
||||
"timestamp": "20250418_115523",
|
||||
"source_agent": "AgentTicketAnalyser",
|
||||
"ticket_id": "T11143",
|
||||
"model_info": {
|
||||
"model": "mistral-large-latest",
|
||||
"temperature": 0.1,
|
||||
"top_p": 0.2,
|
||||
"max_tokens": 7000
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"prompt": "### TICKET T11143\n\n--- MESSAGE INITIAL DU CLIENT ---\nAuteur : GIRAUD TP (JCG), Victor BOLLÉE, v.bollee@labojcg.fr\nDate : 03/04/2025 08:34\nContenu :\nBRGLAB - Essai inaccessible\n*Contenu non extractible*\n\n--- MESSAGE 1 ---\nAuteur : Fabien LAFAY\nDate : 03/04/2025 08:35\nType : Système\nSujet : Re: [T11143] BRGLAB - Essai inaccessible\nContenu :\nGIRAUD TP (JCG), Victor BOLLÉE\n-\nil y a 9 minutes\n;\nFabien LAFAY\n;\nRomuald GRUSON\n;\nsupport\n;\nsupport\n-\nQuentin FAIVRE\n-\nFabien LAFAY\n-\nRomuald GRUSON\nBonjour,\nJe ne parviens pas à accéder au l’essai au bleu :\nMerci par avance pour votre.\nCordialement\n\n\n---\n\n--- MESSAGE 2 ---\nAuteur : Fabien LAFAY\nDate : 03/04/2025 12:17\nType : E-mail\nSujet : Re: [T11143] - BRGLAB - Essai inaccessible\nContenu :\nBonjour\n,\nPouvez-vous vérifier si vous avez bien accès à la page suivante en l'ouvrant dans votre navigateur :\nhttps://zk1.brg-lab.com/\nVoici ce que vous devriez voir affiché :\nSi ce n'est pas le cas, pouvez-vous me faire une capture d'écran de ce qui est affiché?\nJe reste à votre entière disposition pour toute information complémentaire.\nCordialement,\n---\nSupport technique\n\n- image.png (image/png) [ID: 145453]\n\n---\n\n--- MESSAGE 3 ---\nAuteur : Victor BOLLÉE\nDate : 03/04/2025 12:21\nType : E-mail\nSujet : TR: [T11143] - BRGLAB - Essai inaccessible\nContenu :\nBonjour,\nLe problème s’est résolu seul par la suite.\nJe vous remercie pour votre retour.\nBonne journée\nPS : l’adresse fonctionne\nDe :\n\n---\n\n",
|
||||
"response": "### Résumé du contexte\n- **Client** : Victor BOLLÉE, v.bollee@labojcg.fr\n- **Sujet du ticket reformulé en une ou plusieurs questions** :\n - Pourquoi l'essai au bleu est-il inaccessible ?\n - Comment résoudre le problème d'accès à l'essai au bleu ?\n- **Description technique synthétique** :\n - Le client ne parvient pas à accéder à l'essai au bleu.\n - Le problème s'est résolu de lui-même par la suite.\n - L'adresse https://zk1.brg-lab.com/ fonctionne.\n\n### Informations techniques détectées\n- **Logiciels/modules mentionnés** :\n - Essai au bleu\n- **Paramètres évoqués** :\n - Aucun paramètre spécifique mentionné.\n- **Fonctionnalités impactées** :\n - Accès à l'essai au bleu.\n- **Conditions spécifiques** :\n - Aucune condition spécifique mentionnée.\n\n### Fil de discussion (filtrée, nettoyée, classée)\n- **Intervenant** : Victor BOLLÉE (Client)\n - **Date** : 03/04/2025 08:34\n - **Contenu** :\n - Bonjour, Je ne parviens pas à accéder au l’essai au bleu. Merci par avance pour votre. Cordialement\n - **Résumés techniques** :\n - Problème d'accès à l'essai au bleu.\n\n- **Intervenant** : Fabien LAFAY (Support)\n - **Date** : 03/04/2025 12:17\n - **Contenu** :\n - Bonjour, Pouvez-vous vérifier si vous avez bien accès à la page suivante en l'ouvrant dans votre navigateur : https://zk1.brg-lab.com/ Voici ce que vous devriez voir affiché : Si ce n'est pas le cas, pouvez-vous me faire une capture d'écran de ce qui est affiché? Je reste à votre entière disposition pour toute information complémentaire. Cordialement,\n - **Résumés techniques** :\n - Demande de vérification de l'accès à l'URL https://zk1.brg-lab.com/.\n - Demande de capture d'écran si l'affichage n'est pas conforme.\n\n- **Intervenant** : Victor BOLLÉE (Client)\n - **Date** : 03/04/2025 12:21\n - **Contenu** :\n - Bonjour, Le problème s’est résolu seul par la suite. Je vous remercie pour votre retour. Bonne journée PS : l’adresse fonctionne\n - **Résumés techniques** :\n - Le problème d'accès s'est résolu de lui-même.\n - L'adresse https://zk1.brg-lab.com/ fonctionne.\n\n### Éléments liés à l'analyse visuelle\n- **Nombre d'images attachées** : 1\n- **Références aux interfaces ou options à visualiser** :\n - Capture d'écran de l'affichage de la page https://zk1.brg-lab.com/.\n- **Points à vérifier dans les captures** :\n - Vérifier si l'affichage de la page https://zk1.brg-lab.com/ est conforme à ce qui est attendu.",
|
||||
"metadata": {
|
||||
"timestamp": "20250418_144351",
|
||||
"source_agent": "AgentTicketAnalyser",
|
||||
"ticket_id": "T11143",
|
||||
"model_info": {
|
||||
"model": "mistral-large-latest",
|
||||
"temperature": 0.1,
|
||||
"top_p": 0.2,
|
||||
"max_tokens": 7000,
|
||||
"presence_penalty": 0,
|
||||
"frequency_penalty": 0,
|
||||
"stop": [],
|
||||
"stream": false,
|
||||
"n": 1
|
||||
}
|
||||
}
|
||||
}
|
||||
]
|
||||
@ -1,26 +0,0 @@
|
||||
[
|
||||
{
|
||||
"image_path": "output/ticket_T11143/T11143_20250416_103302/attachments/image.png",
|
||||
"status": "unique"
|
||||
},
|
||||
{
|
||||
"image_path": "output/ticket_T11143/T11143_20250416_103302/attachments/image_145435.png",
|
||||
"status": "unique"
|
||||
},
|
||||
{
|
||||
"image_path": "output/ticket_T11143/T11143_20250416_103302/attachments/image_145453.png",
|
||||
"status": "duplicate"
|
||||
},
|
||||
{
|
||||
"image_path": "output/ticket_T11143/T11143_20250416_103302/attachments/543d7da1b54c29ff43ce5712d1a9aa4962ed21795c4e943fcb8cb84fd4d7465a.jpg",
|
||||
"status": "unique"
|
||||
},
|
||||
{
|
||||
"image_path": "output/ticket_T11143/T11143_20250416_103302/attachments/5ad281b63492e31c9e66bf27518b816cdd3766cab9812bd4ff16b736e9e98265.jpg",
|
||||
"status": "duplicate"
|
||||
},
|
||||
{
|
||||
"image_path": "output/ticket_T11143/T11143_20250416_103302/attachments/a20f7697fd5e1d1fca3296c6d01228220e0e112c46b4440cc938f74d10934e98.gif",
|
||||
"status": "unique"
|
||||
}
|
||||
]
|
||||
@ -1,90 +0,0 @@
|
||||
[
|
||||
{
|
||||
"is_relevant": true,
|
||||
"reason": "Oui.\n\nL'image montre une capture d'écran d'une interface web liée à l'installation et à la configuration d'un logiciel (Tomcat), ce qui est pertinent pour un support technique.",
|
||||
"raw_response": "Oui.\n\nL'image montre une capture d'écran d'une interface web liée à l'installation et à la configuration d'un logiciel (Tomcat), ce qui est pertinent pour un support technique.",
|
||||
"metadata": {
|
||||
"image_path": "output/ticket_T11143/T11143_20250416_103302/attachments/image.png",
|
||||
"image_name": "image.png",
|
||||
"timestamp": "20250418_120232",
|
||||
"model_info": {
|
||||
"model": "pixtral-large-latest",
|
||||
"temperature": 0.2,
|
||||
"top_p": 0.8,
|
||||
"max_tokens": 300,
|
||||
"presence_penalty": 0,
|
||||
"frequency_penalty": 0,
|
||||
"stop": [],
|
||||
"stream": false,
|
||||
"n": 1
|
||||
},
|
||||
"source_agent": "AgentImageSorter"
|
||||
}
|
||||
},
|
||||
{
|
||||
"is_relevant": true,
|
||||
"reason": "Oui.\nL'image montre une capture d'écran d'une interface logicielle de BRG-LAB, ce qui est pertinent pour un ticket de support technique.",
|
||||
"raw_response": "Oui.\nL'image montre une capture d'écran d'une interface logicielle de BRG-LAB, ce qui est pertinent pour un ticket de support technique.",
|
||||
"metadata": {
|
||||
"image_path": "output/ticket_T11143/T11143_20250416_103302/attachments/image_145435.png",
|
||||
"image_name": "image_145435.png",
|
||||
"timestamp": "20250418_120238",
|
||||
"model_info": {
|
||||
"model": "pixtral-large-latest",
|
||||
"temperature": 0.2,
|
||||
"top_p": 0.8,
|
||||
"max_tokens": 300,
|
||||
"presence_penalty": 0,
|
||||
"frequency_penalty": 0,
|
||||
"stop": [],
|
||||
"stream": false,
|
||||
"n": 1
|
||||
},
|
||||
"source_agent": "AgentImageSorter"
|
||||
}
|
||||
},
|
||||
{
|
||||
"is_relevant": false,
|
||||
"reason": "Non.\n\nCette image est un logo ou une image de marque (CBAO), ce qui n'est pas pertinent pour un ticket de support technique.",
|
||||
"raw_response": "Non.\n\nCette image est un logo ou une image de marque (CBAO), ce qui n'est pas pertinent pour un ticket de support technique.",
|
||||
"metadata": {
|
||||
"image_path": "output/ticket_T11143/T11143_20250416_103302/attachments/543d7da1b54c29ff43ce5712d1a9aa4962ed21795c4e943fcb8cb84fd4d7465a.jpg",
|
||||
"image_name": "543d7da1b54c29ff43ce5712d1a9aa4962ed21795c4e943fcb8cb84fd4d7465a.jpg",
|
||||
"timestamp": "20250418_120246",
|
||||
"model_info": {
|
||||
"model": "pixtral-large-latest",
|
||||
"temperature": 0.2,
|
||||
"top_p": 0.8,
|
||||
"max_tokens": 300,
|
||||
"presence_penalty": 0,
|
||||
"frequency_penalty": 0,
|
||||
"stop": [],
|
||||
"stream": false,
|
||||
"n": 1
|
||||
},
|
||||
"source_agent": "AgentImageSorter"
|
||||
}
|
||||
},
|
||||
{
|
||||
"is_relevant": false,
|
||||
"reason": "Non.\n\nL'image montre un logo ou une illustration liée à une marque ou une entreprise, sans rapport direct avec un logiciel, une interface technique, ou un problème informatique.",
|
||||
"raw_response": "Non.\n\nL'image montre un logo ou une illustration liée à une marque ou une entreprise, sans rapport direct avec un logiciel, une interface technique, ou un problème informatique.",
|
||||
"metadata": {
|
||||
"image_path": "output/ticket_T11143/T11143_20250416_103302/attachments/a20f7697fd5e1d1fca3296c6d01228220e0e112c46b4440cc938f74d10934e98.gif",
|
||||
"image_name": "a20f7697fd5e1d1fca3296c6d01228220e0e112c46b4440cc938f74d10934e98.gif",
|
||||
"timestamp": "20250418_120257",
|
||||
"model_info": {
|
||||
"model": "pixtral-large-latest",
|
||||
"temperature": 0.2,
|
||||
"top_p": 0.8,
|
||||
"max_tokens": 300,
|
||||
"presence_penalty": 0,
|
||||
"frequency_penalty": 0,
|
||||
"stop": [],
|
||||
"stream": false,
|
||||
"n": 1
|
||||
},
|
||||
"source_agent": "AgentImageSorter"
|
||||
}
|
||||
}
|
||||
]
|
||||
@ -36,7 +36,7 @@
|
||||
"content": "Bonjour,\nLe problème s’est résolu seul par la suite.\nJe vous remercie pour votre retour.\nBonne journée\nPS : l’adresse fonctionne\nDe :\n\n---\n"
|
||||
}
|
||||
],
|
||||
"date_d'extraction": "16/04/2025 10:33:19",
|
||||
"répertoire": "output/ticket_T11143/T11143_20250416_103302",
|
||||
"messages_raw_reference": "output/ticket_T11143/T11143_20250416_103302/messages_raw.json"
|
||||
"date_d'extraction": "18/04/2025 15:17:37",
|
||||
"répertoire": "output/ticket_T11143/T11143_20250418_151735",
|
||||
"messages_raw_reference": "output/ticket_T11143/T11143_20250418_151735/messages_raw.json"
|
||||
}
|
||||
@ -89,5 +89,5 @@ De :
|
||||
|
||||
## Informations sur l'extraction
|
||||
|
||||
- **Date d'extraction**: 16/04/2025 10:33:19
|
||||
- **Répertoire**: output/ticket_T11143/T11143_20250416_103302
|
||||
- **Date d'extraction**: 18/04/2025 15:17:37
|
||||
- **Répertoire**: output/ticket_T11143/T11143_20250418_151735
|
||||
@ -7,7 +7,7 @@
|
||||
"project_name": "Demandes",
|
||||
"stage_id": 8,
|
||||
"stage_name": "Clôturé",
|
||||
"date_extraction": "2025-04-16T10:33:02.745244"
|
||||
"date_extraction": "2025-04-18T15:17:36.666082"
|
||||
},
|
||||
"metadata": {
|
||||
"message_count": {
|
||||
@ -1,5 +1,5 @@
|
||||
TICKET: T11143 - BRGLAB - Essai inaccessible
|
||||
Date d'extraction: 2025-04-16 10:33:02
|
||||
Date d'extraction: 2025-04-18 15:17:36
|
||||
Nombre de messages: 7
|
||||
|
||||
================================================================================
|
||||
{kind=link}
|
Before Width: | Height: | Size: 10 KiB After Width: | Height: | Size: 10 KiB |
|
Before Width: | Height: | Size: 43 B After Width: | Height: | Size: 43 B |
{kind=link}
|
Before Width: | Height: | Size: 36 KiB After Width: | Height: | Size: 36 KiB |
{kind=link}
|
Before Width: | Height: | Size: 43 B After Width: | Height: | Size: 43 B |
{kind=link}
|
Before Width: | Height: | Size: 75 KiB After Width: | Height: | Size: 75 KiB |
{kind=link}
|
Before Width: | Height: | Size: 25 KiB After Width: | Height: | Size: 25 KiB |
{kind=link}
|
Before Width: | Height: | Size: 75 KiB After Width: | Height: | Size: 75 KiB |
@ -14,7 +14,7 @@
|
||||
"creator_name": "Fabien LAFAY",
|
||||
"creator_id": 22,
|
||||
"download_status": "success",
|
||||
"local_path": "output/ticket_T11143/T11143_20250416_103302/attachments/image.png",
|
||||
"local_path": "output/ticket_T11143/T11143_20250418_151735/attachments/image.png",
|
||||
"error": ""
|
||||
},
|
||||
{
|
||||
@ -25,29 +25,29 @@
|
||||
"create_date": null,
|
||||
"creator_name": "Extraction automatique",
|
||||
"download_status": "success",
|
||||
"local_path": "output/ticket_T11143/T11143_20250416_103302/attachments/543d7da1b54c29ff43ce5712d1a9aa4962ed21795c4e943fcb8cb84fd4d7465a.jpg",
|
||||
"local_path": "output/ticket_T11143/T11143_20250418_151735/attachments/543d7da1b54c29ff43ce5712d1a9aa4962ed21795c4e943fcb8cb84fd4d7465a.jpg",
|
||||
"error": "",
|
||||
"is_embedded_image": true,
|
||||
"source_url": "https://img.mail.cbao.fr/im/2881244/543d7da1b54c29ff43ce5712d1a9aa4962ed21795c4e943fcb8cb84fd4d7465a.jpg?e=kEDXgN0xHfEb-981h_lc_yULm91O7bZKL_LYGfrT2K86Ta7cu921uClZUdgMhvotDWlcCzD3lJtBuoEhqI1Gywup4qaf3_WKJ6oubZu7p_5Stx-yi0SEGpWmdZd7tnRqk39JBwZTv6QvJDmP-3-8a_GVN6XIVj2mk65O7ASevFoYG54BN1Bzy0CebDYuMGOLCZGigDc_ZfReFYMsdxNdUnxNy9uoEFa9wO6djoxvs6pAQkJdPyaJMbf-vC-scsOjG4mbDhUUNKk",
|
||||
"source": "message_embedded",
|
||||
"extraction_date": "2025-04-16T10:33:02.924675",
|
||||
"extraction_date": "2025-04-18T15:17:36.840268",
|
||||
"source_message_id": 228971,
|
||||
"message_author": "GIRAUD TP (JCG), Victor BOLLÉE"
|
||||
},
|
||||
{
|
||||
"id": "embedded_3",
|
||||
"name": "5ad281b63492e31c9e66bf27518b816cdd3766cab9812bd4ff16b736e9e98265.jpg",
|
||||
"mimetype": "image/jpeg",
|
||||
"file_size": "36638",
|
||||
"name": "5JbLgq7JMCd0cW4WUA-lgvTWXWdoLO1_ucWlr1Lq-Aahl3ciesDgM6O8PTgP7DJSRVCBx5lLZeGCOG9eZyn5F6PdDURFrtnzk...",
|
||||
"mimetype": "application/octet-stream",
|
||||
"file_size": "43",
|
||||
"create_date": null,
|
||||
"creator_name": "Extraction automatique",
|
||||
"download_status": "success",
|
||||
"local_path": "output/ticket_T11143/T11143_20250416_103302/attachments/5ad281b63492e31c9e66bf27518b816cdd3766cab9812bd4ff16b736e9e98265.jpg",
|
||||
"local_path": "output/ticket_T11143/T11143_20250418_151735/attachments/5JbLgq7JMCd0cW4WUA-lgvTWXWdoLO1_ucWlr1Lq-Aahl3ciesDgM6O8PTgP7DJSRVCBx5lLZeGCOG9eZyn5F6PdDURFrtnzk...",
|
||||
"error": "",
|
||||
"is_embedded_image": true,
|
||||
"source_url": "https://img.mail.cbao.fr/im/2881244/5ad281b63492e31c9e66bf27518b816cdd3766cab9812bd4ff16b736e9e98265.jpg?e=8r2BeeTx41o7P48QGc8dTA9QZOB2GTlwPmvmUKM1mOEj7PIixgxi8THfMHUzkbxvWZ0IeDNk2GLdKrFDTFmFNUwsuze9m9iIGLsevTWvi9J0FKdCiHPM_N7oHl28BaOgXNM5hJnnQQiBDTuFH9yOdwtANlSU-In61mRTQcU059dPwIa6d7cW4mYPKAM316uk4wF5BzQTalI2490N3xfQO-NGNQq2w2JAiGOTUvWOI05ZCSyZ-qmoLbTFg6P9dUskVN6qx6F1PpKND8esvfmxiTdAIV1_tvg6owg8U_MCtUp8laoDr4Si8qIIDu02_ZtzEOxPW9rG0WCFcwx3",
|
||||
"source_url": "http://r.mail.cbao.fr/tr/op/5JbLgq7JMCd0cW4WUA-lgvTWXWdoLO1_ucWlr1Lq-Aahl3ciesDgM6O8PTgP7DJSRVCBx5lLZeGCOG9eZyn5F6PdDURFrtnzkWtHz8COpP16VAIdOWIpK8w_elOaV8Zi2U1ZjvCAMpCqfCYJYDADVxV2xRjq3plCjFMQ-FWOfmWoDIFWxksfoc2I5mhhnsrw",
|
||||
"source": "message_embedded",
|
||||
"extraction_date": "2025-04-16T10:33:03.012335",
|
||||
"extraction_date": "2025-04-18T15:17:36.940589",
|
||||
"source_message_id": 228971,
|
||||
"message_author": "GIRAUD TP (JCG), Victor BOLLÉE"
|
||||
},
|
||||
@ -59,63 +59,63 @@
|
||||
"create_date": null,
|
||||
"creator_name": "Extraction automatique",
|
||||
"download_status": "success",
|
||||
"local_path": "output/ticket_T11143/T11143_20250416_103302/attachments/image_145435.png",
|
||||
"local_path": "output/ticket_T11143/T11143_20250418_151735/attachments/image_145435.png",
|
||||
"error": "",
|
||||
"is_embedded_image": true,
|
||||
"source_url": "https://odoo.cbao.fr/web/image/145435?access_token=608ac9e7-3627-4a13-a8ec-06ff5046ebf3",
|
||||
"source": "message_embedded",
|
||||
"extraction_date": "2025-04-16T10:33:03.179674",
|
||||
"extraction_date": "2025-04-18T15:17:37.057453",
|
||||
"source_message_id": 228942,
|
||||
"message_author": "Fabien LAFAY"
|
||||
},
|
||||
{
|
||||
"id": "embedded_5",
|
||||
"name": "5JbLgq7JMCd0cW4WUA-lgvTWXWdoLO1_ucWlr1Lq-Aahl3ciesDgM6O8PTgP7DJSRVCBx5lLZeGCOG9eZyn5F6PdDURFrtnzk...",
|
||||
"mimetype": "application/octet-stream",
|
||||
"file_size": "43",
|
||||
"create_date": null,
|
||||
"creator_name": "Extraction automatique",
|
||||
"download_status": "success",
|
||||
"local_path": "output/ticket_T11143/T11143_20250416_103302/attachments/5JbLgq7JMCd0cW4WUA-lgvTWXWdoLO1_ucWlr1Lq-Aahl3ciesDgM6O8PTgP7DJSRVCBx5lLZeGCOG9eZyn5F6PdDURFrtnzk...",
|
||||
"error": "",
|
||||
"is_embedded_image": true,
|
||||
"source_url": "http://r.mail.cbao.fr/tr/op/5JbLgq7JMCd0cW4WUA-lgvTWXWdoLO1_ucWlr1Lq-Aahl3ciesDgM6O8PTgP7DJSRVCBx5lLZeGCOG9eZyn5F6PdDURFrtnzkWtHz8COpP16VAIdOWIpK8w_elOaV8Zi2U1ZjvCAMpCqfCYJYDADVxV2xRjq3plCjFMQ-FWOfmWoDIFWxksfoc2I5mhhnsrw",
|
||||
"source": "message_embedded",
|
||||
"extraction_date": "2025-04-16T10:33:03.322154",
|
||||
"source_message_id": 228971,
|
||||
"message_author": "GIRAUD TP (JCG), Victor BOLLÉE"
|
||||
},
|
||||
{
|
||||
"id": "embedded_6",
|
||||
"name": "image_145453.png",
|
||||
"mimetype": "image/png",
|
||||
"file_size": "76543",
|
||||
"create_date": null,
|
||||
"creator_name": "Extraction automatique",
|
||||
"download_status": "success",
|
||||
"local_path": "output/ticket_T11143/T11143_20250416_103302/attachments/image_145453.png",
|
||||
"local_path": "output/ticket_T11143/T11143_20250418_151735/attachments/image_145453.png",
|
||||
"error": "",
|
||||
"is_embedded_image": true,
|
||||
"source_url": "https://odoo.cbao.fr/web/image/145453?access_token=9c5d3a29-fce3-411f-8973-e3f33aa8f32c",
|
||||
"source": "message_embedded",
|
||||
"extraction_date": "2025-04-16T10:33:03.456800",
|
||||
"extraction_date": "2025-04-18T15:17:37.209384",
|
||||
"source_message_id": "",
|
||||
"message_author": ""
|
||||
},
|
||||
{
|
||||
"id": "embedded_7",
|
||||
"id": "embedded_6",
|
||||
"name": "a20f7697fd5e1d1fca3296c6d01228220e0e112c46b4440cc938f74d10934e98.gif",
|
||||
"mimetype": "image/gif",
|
||||
"file_size": "43",
|
||||
"create_date": null,
|
||||
"creator_name": "Extraction automatique",
|
||||
"download_status": "success",
|
||||
"local_path": "output/ticket_T11143/T11143_20250416_103302/attachments/a20f7697fd5e1d1fca3296c6d01228220e0e112c46b4440cc938f74d10934e98.gif",
|
||||
"local_path": "output/ticket_T11143/T11143_20250418_151735/attachments/a20f7697fd5e1d1fca3296c6d01228220e0e112c46b4440cc938f74d10934e98.gif",
|
||||
"error": "",
|
||||
"is_embedded_image": true,
|
||||
"source_url": "https://img.mail.cbao.fr/im/2881244/a20f7697fd5e1d1fca3296c6d01228220e0e112c46b4440cc938f74d10934e98.gif?e=J3oCbkWCHi7Jby6t0tMcS8mUioUDEMsJYthetssCVJI9F79WEhd03wXCmZ-MpVe_3kKAdx_UKcZh7LDpl4Os8alPD1hBRHXiL-2qkQEj4lUqUFcIVU3DjuHacMF2VQ1IaigOvBjMSkWrj63_l83dijq9mRqTXSs49fj4n3V7dQhw4xsQKlsroCMU2-_4smR8gNanwzu5M8xZrnbT6s3ze-l71gRqWBrO_iZDm8k3tZTQiEd0IHK_ydL2M7nO2Yqs1hKQsm0BdJW0RoUsbN51VgDXaWpY-XAoBAsEzhDdTyZcNdbwIaGtdhY9TXI72Egw6rdZ69UNJpQ4HuFZOJNYcFm6uCA0LxwFmx5n7nnYcYyY",
|
||||
"source": "message_embedded",
|
||||
"extraction_date": "2025-04-16T10:33:03.548952",
|
||||
"extraction_date": "2025-04-18T15:17:37.295792",
|
||||
"source_message_id": 228971,
|
||||
"message_author": "GIRAUD TP (JCG), Victor BOLLÉE"
|
||||
},
|
||||
{
|
||||
"id": "embedded_7",
|
||||
"name": "5ad281b63492e31c9e66bf27518b816cdd3766cab9812bd4ff16b736e9e98265.jpg",
|
||||
"mimetype": "image/jpeg",
|
||||
"file_size": "36638",
|
||||
"create_date": null,
|
||||
"creator_name": "Extraction automatique",
|
||||
"download_status": "success",
|
||||
"local_path": "output/ticket_T11143/T11143_20250418_151735/attachments/5ad281b63492e31c9e66bf27518b816cdd3766cab9812bd4ff16b736e9e98265.jpg",
|
||||
"error": "",
|
||||
"is_embedded_image": true,
|
||||
"source_url": "https://img.mail.cbao.fr/im/2881244/5ad281b63492e31c9e66bf27518b816cdd3766cab9812bd4ff16b736e9e98265.jpg?e=8r2BeeTx41o7P48QGc8dTA9QZOB2GTlwPmvmUKM1mOEj7PIixgxi8THfMHUzkbxvWZ0IeDNk2GLdKrFDTFmFNUwsuze9m9iIGLsevTWvi9J0FKdCiHPM_N7oHl28BaOgXNM5hJnnQQiBDTuFH9yOdwtANlSU-In61mRTQcU059dPwIa6d7cW4mYPKAM316uk4wF5BzQTalI2490N3xfQO-NGNQq2w2JAiGOTUvWOI05ZCSyZ-qmoLbTFg6P9dUskVN6qx6F1PpKND8esvfmxiTdAIV1_tvg6owg8U_MCtUp8laoDr4Si8qIIDu02_ZtzEOxPW9rG0WCFcwx3",
|
||||
"source": "message_embedded",
|
||||
"extraction_date": "2025-04-18T15:17:37.392688",
|
||||
"source_message_id": 228971,
|
||||
"message_author": "GIRAUD TP (JCG), Victor BOLLÉE"
|
||||
}
|
||||
@ -0,0 +1,13 @@
|
||||
{
|
||||
"timestamp": "20250418_151735",
|
||||
"ticket_code": "T11143",
|
||||
"output_directory": "output/ticket_T11143/T11143_20250418_151735",
|
||||
"message_count": 7,
|
||||
"attachment_count": 7,
|
||||
"files_created": [
|
||||
"ticket_info.json",
|
||||
"ticket_summary.json",
|
||||
"all_messages.json",
|
||||
"structure.json"
|
||||
]
|
||||
}
|
||||
@ -1,9 +1,9 @@
|
||||
{
|
||||
"date_extraction": "2025-04-16T10:33:03.585561",
|
||||
"date_extraction": "2025-04-18T15:17:37.426186",
|
||||
"ticket_id": 11122,
|
||||
"ticket_code": "T11143",
|
||||
"ticket_name": "BRGLAB - Essai inaccessible",
|
||||
"output_dir": "output/ticket_T11143/T11143_20250416_103302",
|
||||
"output_dir": "output/ticket_T11143/T11143_20250418_151735",
|
||||
"files": {
|
||||
"ticket_info": "ticket_info.json",
|
||||
"ticket_summary": "ticket_summary.json",
|
||||
@ -559,3 +559,118 @@
|
||||
2025-04-16 10:35:23 - root - INFO - Messages traités: 6
|
||||
2025-04-16 10:35:23 - root - INFO - Pièces jointes: 5
|
||||
2025-04-16 10:35:23 - root - INFO - ------------------------------------------------------------
|
||||
2025-04-18 15:02:08 - root - INFO - Extraction du ticket T11143
|
||||
2025-04-18 15:02:08 - root - INFO - ------------------------------------------------------------
|
||||
2025-04-18 15:02:09 - root - INFO - Données des messages chargées pour l'extraction des images intégrées
|
||||
2025-04-18 15:02:09 - root - INFO - Traitement de 1 pièces jointes pour le ticket 11122
|
||||
2025-04-18 15:02:09 - root - INFO - Pièce jointe téléchargée: image.png (1/1)
|
||||
2025-04-18 15:02:09 - root - INFO - Extraction des images intégrées aux messages...
|
||||
2025-04-18 15:02:09 - root - INFO - URLs d'images trouvées dans les messages: 10
|
||||
2025-04-18 15:02:09 - root - INFO - Image téléchargée depuis l'URL: https://odoo.cbao.fr/web/image/145435?access_token=608ac9e7-3627-4a13-a8ec-06ff5046ebf3
|
||||
2025-04-18 15:02:09 - root - INFO - Image téléchargée depuis l'URL: https://img.mail.cbao.fr/im/2881244/5ad281b63492e31c9e66bf27518b816cdd3766cab9812bd4ff16b736e9e98265.jpg?e=8r2BeeTx41o7P48QGc8dTA9QZOB2GTlwPmvmUKM1mOEj7PIixgxi8THfMHUzkbxvWZ0IeDNk2GLdKrFDTFmFNUwsuze9m9iIGLsevTWvi9J0FKdCiHPM_N7oHl28BaOgXNM5hJnnQQiBDTuFH9yOdwtANlSU-In61mRTQcU059dPwIa6d7cW4mYPKAM316uk4wF5BzQTalI2490N3xfQO-NGNQq2w2JAiGOTUvWOI05ZCSyZ-qmoLbTFg6P9dUskVN6qx6F1PpKND8esvfmxiTdAIV1_tvg6owg8U_MCtUp8laoDr4Si8qIIDu02_ZtzEOxPW9rG0WCFcwx3
|
||||
2025-04-18 15:02:09 - root - ERROR - Erreur lors du téléchargement de l'image depuis /web_editor/font_to_img/61443/rgb(173,181,189)/13: Invalid URL '/web_editor/font_to_img/61443/rgb(173,181,189)/13': No scheme supplied. Perhaps you meant https:///web_editor/font_to_img/61443/rgb(173,181,189)/13?
|
||||
2025-04-18 15:02:09 - root - INFO - Image téléchargée depuis l'URL: https://img.mail.cbao.fr/im/2881244/a20f7697fd5e1d1fca3296c6d01228220e0e112c46b4440cc938f74d10934e98.gif?e=J3oCbkWCHi7Jby6t0tMcS8mUioUDEMsJYthetssCVJI9F79WEhd03wXCmZ-MpVe_3kKAdx_UKcZh7LDpl4Os8alPD1hBRHXiL-2qkQEj4lUqUFcIVU3DjuHacMF2VQ1IaigOvBjMSkWrj63_l83dijq9mRqTXSs49fj4n3V7dQhw4xsQKlsroCMU2-_4smR8gNanwzu5M8xZrnbT6s3ze-l71gRqWBrO_iZDm8k3tZTQiEd0IHK_ydL2M7nO2Yqs1hKQsm0BdJW0RoUsbN51VgDXaWpY-XAoBAsEzhDdTyZcNdbwIaGtdhY9TXI72Egw6rdZ69UNJpQ4HuFZOJNYcFm6uCA0LxwFmx5n7nnYcYyY
|
||||
2025-04-18 15:02:09 - root - INFO - Image téléchargée depuis l'URL: https://img.mail.cbao.fr/im/2881244/543d7da1b54c29ff43ce5712d1a9aa4962ed21795c4e943fcb8cb84fd4d7465a.jpg?e=kEDXgN0xHfEb-981h_lc_yULm91O7bZKL_LYGfrT2K86Ta7cu921uClZUdgMhvotDWlcCzD3lJtBuoEhqI1Gywup4qaf3_WKJ6oubZu7p_5Stx-yi0SEGpWmdZd7tnRqk39JBwZTv6QvJDmP-3-8a_GVN6XIVj2mk65O7ASevFoYG54BN1Bzy0CebDYuMGOLCZGigDc_ZfReFYMsdxNdUnxNy9uoEFa9wO6djoxvs6pAQkJdPyaJMbf-vC-scsOjG4mbDhUUNKk
|
||||
2025-04-18 15:02:09 - root - ERROR - Erreur lors du téléchargement de l'image depuis /web_editor/font_to_img/61618/rgb(173,181,189)/13: Invalid URL '/web_editor/font_to_img/61618/rgb(173,181,189)/13': No scheme supplied. Perhaps you meant https:///web_editor/font_to_img/61618/rgb(173,181,189)/13?
|
||||
2025-04-18 15:02:09 - root - ERROR - Erreur lors du téléchargement de l'image depuis /web_editor/font_to_img/61534/rgb(144,144,144)/13: Invalid URL '/web_editor/font_to_img/61534/rgb(144,144,144)/13': No scheme supplied. Perhaps you meant https:///web_editor/font_to_img/61534/rgb(144,144,144)/13?
|
||||
2025-04-18 15:02:09 - root - ERROR - Erreur lors du téléchargement de l'image depuis /web_editor/font_to_img/61446/rgb(173,181,189)/13: Invalid URL '/web_editor/font_to_img/61446/rgb(173,181,189)/13': No scheme supplied. Perhaps you meant https:///web_editor/font_to_img/61446/rgb(173,181,189)/13?
|
||||
2025-04-18 15:02:10 - root - INFO - Image téléchargée depuis l'URL: https://odoo.cbao.fr/web/image/145453?access_token=9c5d3a29-fce3-411f-8973-e3f33aa8f32c
|
||||
2025-04-18 15:02:10 - root - INFO - Image téléchargée depuis l'URL: http://r.mail.cbao.fr/tr/op/5JbLgq7JMCd0cW4WUA-lgvTWXWdoLO1_ucWlr1Lq-Aahl3ciesDgM6O8PTgP7DJSRVCBx5lLZeGCOG9eZyn5F6PdDURFrtnzkWtHz8COpP16VAIdOWIpK8w_elOaV8Zi2U1ZjvCAMpCqfCYJYDADVxV2xRjq3plCjFMQ-FWOfmWoDIFWxksfoc2I5mhhnsrw
|
||||
2025-04-18 15:02:10 - root - INFO - Total des images extraites: 6
|
||||
2025-04-18 15:02:10 - root - INFO - 6 images intégrées extraites et ajoutées aux pièces jointes
|
||||
2025-04-18 15:02:10 - root - INFO - ------------------------------------------------------------
|
||||
2025-04-18 15:02:10 - root - INFO - Extraction terminée avec succès
|
||||
2025-04-18 15:02:10 - root - INFO - Ticket: T11143
|
||||
2025-04-18 15:02:10 - root - INFO - Répertoire: output/ticket_T11143/T11143_20250418_150208
|
||||
2025-04-18 15:02:10 - root - INFO - Messages traités: 7
|
||||
2025-04-18 15:02:10 - root - INFO - Pièces jointes: 7
|
||||
2025-04-18 15:02:10 - root - INFO - ------------------------------------------------------------
|
||||
2025-04-18 15:10:00 - root - INFO - Extraction du ticket T11143
|
||||
2025-04-18 15:10:00 - root - INFO - ------------------------------------------------------------
|
||||
2025-04-18 15:10:00 - root - INFO - Données des messages chargées pour l'extraction des images intégrées
|
||||
2025-04-18 15:10:00 - root - INFO - Traitement de 1 pièces jointes pour le ticket 11122
|
||||
2025-04-18 15:10:00 - root - INFO - Pièce jointe téléchargée: image.png (1/1)
|
||||
2025-04-18 15:10:00 - root - INFO - Extraction des images intégrées aux messages...
|
||||
2025-04-18 15:10:00 - root - INFO - URLs d'images trouvées dans les messages: 10
|
||||
2025-04-18 15:10:00 - root - ERROR - Erreur lors du téléchargement de l'image depuis /web_editor/font_to_img/61534/rgb(144,144,144)/13: Invalid URL '/web_editor/font_to_img/61534/rgb(144,144,144)/13': No scheme supplied. Perhaps you meant https:///web_editor/font_to_img/61534/rgb(144,144,144)/13?
|
||||
2025-04-18 15:10:01 - root - INFO - Image téléchargée depuis l'URL: https://img.mail.cbao.fr/im/2881244/543d7da1b54c29ff43ce5712d1a9aa4962ed21795c4e943fcb8cb84fd4d7465a.jpg?e=kEDXgN0xHfEb-981h_lc_yULm91O7bZKL_LYGfrT2K86Ta7cu921uClZUdgMhvotDWlcCzD3lJtBuoEhqI1Gywup4qaf3_WKJ6oubZu7p_5Stx-yi0SEGpWmdZd7tnRqk39JBwZTv6QvJDmP-3-8a_GVN6XIVj2mk65O7ASevFoYG54BN1Bzy0CebDYuMGOLCZGigDc_ZfReFYMsdxNdUnxNy9uoEFa9wO6djoxvs6pAQkJdPyaJMbf-vC-scsOjG4mbDhUUNKk
|
||||
2025-04-18 15:10:01 - root - ERROR - Erreur lors du téléchargement de l'image depuis /web_editor/font_to_img/61618/rgb(173,181,189)/13: Invalid URL '/web_editor/font_to_img/61618/rgb(173,181,189)/13': No scheme supplied. Perhaps you meant https:///web_editor/font_to_img/61618/rgb(173,181,189)/13?
|
||||
2025-04-18 15:10:01 - root - INFO - Image téléchargée depuis l'URL: http://r.mail.cbao.fr/tr/op/5JbLgq7JMCd0cW4WUA-lgvTWXWdoLO1_ucWlr1Lq-Aahl3ciesDgM6O8PTgP7DJSRVCBx5lLZeGCOG9eZyn5F6PdDURFrtnzkWtHz8COpP16VAIdOWIpK8w_elOaV8Zi2U1ZjvCAMpCqfCYJYDADVxV2xRjq3plCjFMQ-FWOfmWoDIFWxksfoc2I5mhhnsrw
|
||||
2025-04-18 15:10:01 - root - ERROR - Erreur lors du téléchargement de l'image depuis /web_editor/font_to_img/61446/rgb(173,181,189)/13: Invalid URL '/web_editor/font_to_img/61446/rgb(173,181,189)/13': No scheme supplied. Perhaps you meant https:///web_editor/font_to_img/61446/rgb(173,181,189)/13?
|
||||
2025-04-18 15:10:01 - root - ERROR - Erreur lors du téléchargement de l'image depuis /web_editor/font_to_img/61443/rgb(173,181,189)/13: Invalid URL '/web_editor/font_to_img/61443/rgb(173,181,189)/13': No scheme supplied. Perhaps you meant https:///web_editor/font_to_img/61443/rgb(173,181,189)/13?
|
||||
2025-04-18 15:10:01 - root - INFO - Image téléchargée depuis l'URL: https://img.mail.cbao.fr/im/2881244/5ad281b63492e31c9e66bf27518b816cdd3766cab9812bd4ff16b736e9e98265.jpg?e=8r2BeeTx41o7P48QGc8dTA9QZOB2GTlwPmvmUKM1mOEj7PIixgxi8THfMHUzkbxvWZ0IeDNk2GLdKrFDTFmFNUwsuze9m9iIGLsevTWvi9J0FKdCiHPM_N7oHl28BaOgXNM5hJnnQQiBDTuFH9yOdwtANlSU-In61mRTQcU059dPwIa6d7cW4mYPKAM316uk4wF5BzQTalI2490N3xfQO-NGNQq2w2JAiGOTUvWOI05ZCSyZ-qmoLbTFg6P9dUskVN6qx6F1PpKND8esvfmxiTdAIV1_tvg6owg8U_MCtUp8laoDr4Si8qIIDu02_ZtzEOxPW9rG0WCFcwx3
|
||||
2025-04-18 15:10:01 - root - INFO - Image téléchargée depuis l'URL: https://img.mail.cbao.fr/im/2881244/a20f7697fd5e1d1fca3296c6d01228220e0e112c46b4440cc938f74d10934e98.gif?e=J3oCbkWCHi7Jby6t0tMcS8mUioUDEMsJYthetssCVJI9F79WEhd03wXCmZ-MpVe_3kKAdx_UKcZh7LDpl4Os8alPD1hBRHXiL-2qkQEj4lUqUFcIVU3DjuHacMF2VQ1IaigOvBjMSkWrj63_l83dijq9mRqTXSs49fj4n3V7dQhw4xsQKlsroCMU2-_4smR8gNanwzu5M8xZrnbT6s3ze-l71gRqWBrO_iZDm8k3tZTQiEd0IHK_ydL2M7nO2Yqs1hKQsm0BdJW0RoUsbN51VgDXaWpY-XAoBAsEzhDdTyZcNdbwIaGtdhY9TXI72Egw6rdZ69UNJpQ4HuFZOJNYcFm6uCA0LxwFmx5n7nnYcYyY
|
||||
2025-04-18 15:10:01 - root - INFO - Image téléchargée depuis l'URL: https://odoo.cbao.fr/web/image/145453?access_token=9c5d3a29-fce3-411f-8973-e3f33aa8f32c
|
||||
2025-04-18 15:10:01 - root - INFO - Image téléchargée depuis l'URL: https://odoo.cbao.fr/web/image/145435?access_token=608ac9e7-3627-4a13-a8ec-06ff5046ebf3
|
||||
2025-04-18 15:10:01 - root - INFO - Total des images extraites: 6
|
||||
2025-04-18 15:10:01 - root - INFO - 6 images intégrées extraites et ajoutées aux pièces jointes
|
||||
2025-04-18 15:10:01 - root - INFO - ------------------------------------------------------------
|
||||
2025-04-18 15:10:01 - root - INFO - Extraction terminée avec succès
|
||||
2025-04-18 15:10:01 - root - INFO - Ticket: T11143
|
||||
2025-04-18 15:10:01 - root - INFO - Répertoire: output/ticket_T11143/T11143_20250418_151000
|
||||
2025-04-18 15:10:01 - root - INFO - Messages traités: 7
|
||||
2025-04-18 15:10:01 - root - INFO - Pièces jointes: 7
|
||||
2025-04-18 15:10:01 - root - INFO - ------------------------------------------------------------
|
||||
2025-04-18 15:11:24 - root - INFO - Extraction du ticket T11143
|
||||
2025-04-18 15:11:24 - root - INFO - ------------------------------------------------------------
|
||||
2025-04-18 15:11:25 - root - INFO - Données des messages chargées pour l'extraction des images intégrées
|
||||
2025-04-18 15:11:25 - root - INFO - Traitement de 1 pièces jointes pour le ticket 11122
|
||||
2025-04-18 15:11:25 - root - INFO - Pièce jointe téléchargée: image.png (1/1)
|
||||
2025-04-18 15:11:25 - root - INFO - Extraction des images intégrées aux messages...
|
||||
2025-04-18 15:11:25 - root - INFO - URLs d'images trouvées dans les messages: 10
|
||||
2025-04-18 15:11:25 - root - INFO - Image téléchargée depuis l'URL: https://img.mail.cbao.fr/im/2881244/5ad281b63492e31c9e66bf27518b816cdd3766cab9812bd4ff16b736e9e98265.jpg?e=8r2BeeTx41o7P48QGc8dTA9QZOB2GTlwPmvmUKM1mOEj7PIixgxi8THfMHUzkbxvWZ0IeDNk2GLdKrFDTFmFNUwsuze9m9iIGLsevTWvi9J0FKdCiHPM_N7oHl28BaOgXNM5hJnnQQiBDTuFH9yOdwtANlSU-In61mRTQcU059dPwIa6d7cW4mYPKAM316uk4wF5BzQTalI2490N3xfQO-NGNQq2w2JAiGOTUvWOI05ZCSyZ-qmoLbTFg6P9dUskVN6qx6F1PpKND8esvfmxiTdAIV1_tvg6owg8U_MCtUp8laoDr4Si8qIIDu02_ZtzEOxPW9rG0WCFcwx3
|
||||
2025-04-18 15:11:25 - root - INFO - Image téléchargée depuis l'URL: https://odoo.cbao.fr/web/image/145435?access_token=608ac9e7-3627-4a13-a8ec-06ff5046ebf3
|
||||
2025-04-18 15:11:25 - root - ERROR - Erreur lors du téléchargement de l'image depuis /web_editor/font_to_img/61446/rgb(173,181,189)/13: Invalid URL '/web_editor/font_to_img/61446/rgb(173,181,189)/13': No scheme supplied. Perhaps you meant https:///web_editor/font_to_img/61446/rgb(173,181,189)/13?
|
||||
2025-04-18 15:11:25 - root - INFO - Image téléchargée depuis l'URL: https://img.mail.cbao.fr/im/2881244/a20f7697fd5e1d1fca3296c6d01228220e0e112c46b4440cc938f74d10934e98.gif?e=J3oCbkWCHi7Jby6t0tMcS8mUioUDEMsJYthetssCVJI9F79WEhd03wXCmZ-MpVe_3kKAdx_UKcZh7LDpl4Os8alPD1hBRHXiL-2qkQEj4lUqUFcIVU3DjuHacMF2VQ1IaigOvBjMSkWrj63_l83dijq9mRqTXSs49fj4n3V7dQhw4xsQKlsroCMU2-_4smR8gNanwzu5M8xZrnbT6s3ze-l71gRqWBrO_iZDm8k3tZTQiEd0IHK_ydL2M7nO2Yqs1hKQsm0BdJW0RoUsbN51VgDXaWpY-XAoBAsEzhDdTyZcNdbwIaGtdhY9TXI72Egw6rdZ69UNJpQ4HuFZOJNYcFm6uCA0LxwFmx5n7nnYcYyY
|
||||
2025-04-18 15:11:25 - root - INFO - Image téléchargée depuis l'URL: https://img.mail.cbao.fr/im/2881244/543d7da1b54c29ff43ce5712d1a9aa4962ed21795c4e943fcb8cb84fd4d7465a.jpg?e=kEDXgN0xHfEb-981h_lc_yULm91O7bZKL_LYGfrT2K86Ta7cu921uClZUdgMhvotDWlcCzD3lJtBuoEhqI1Gywup4qaf3_WKJ6oubZu7p_5Stx-yi0SEGpWmdZd7tnRqk39JBwZTv6QvJDmP-3-8a_GVN6XIVj2mk65O7ASevFoYG54BN1Bzy0CebDYuMGOLCZGigDc_ZfReFYMsdxNdUnxNy9uoEFa9wO6djoxvs6pAQkJdPyaJMbf-vC-scsOjG4mbDhUUNKk
|
||||
2025-04-18 15:11:25 - root - ERROR - Erreur lors du téléchargement de l'image depuis /web_editor/font_to_img/61534/rgb(144,144,144)/13: Invalid URL '/web_editor/font_to_img/61534/rgb(144,144,144)/13': No scheme supplied. Perhaps you meant https:///web_editor/font_to_img/61534/rgb(144,144,144)/13?
|
||||
2025-04-18 15:11:25 - root - ERROR - Erreur lors du téléchargement de l'image depuis /web_editor/font_to_img/61618/rgb(173,181,189)/13: Invalid URL '/web_editor/font_to_img/61618/rgb(173,181,189)/13': No scheme supplied. Perhaps you meant https:///web_editor/font_to_img/61618/rgb(173,181,189)/13?
|
||||
2025-04-18 15:11:25 - root - INFO - Image téléchargée depuis l'URL: https://odoo.cbao.fr/web/image/145453?access_token=9c5d3a29-fce3-411f-8973-e3f33aa8f32c
|
||||
2025-04-18 15:11:25 - root - ERROR - Erreur lors du téléchargement de l'image depuis /web_editor/font_to_img/61443/rgb(173,181,189)/13: Invalid URL '/web_editor/font_to_img/61443/rgb(173,181,189)/13': No scheme supplied. Perhaps you meant https:///web_editor/font_to_img/61443/rgb(173,181,189)/13?
|
||||
2025-04-18 15:11:25 - root - INFO - Image téléchargée depuis l'URL: http://r.mail.cbao.fr/tr/op/5JbLgq7JMCd0cW4WUA-lgvTWXWdoLO1_ucWlr1Lq-Aahl3ciesDgM6O8PTgP7DJSRVCBx5lLZeGCOG9eZyn5F6PdDURFrtnzkWtHz8COpP16VAIdOWIpK8w_elOaV8Zi2U1ZjvCAMpCqfCYJYDADVxV2xRjq3plCjFMQ-FWOfmWoDIFWxksfoc2I5mhhnsrw
|
||||
2025-04-18 15:11:25 - root - INFO - Total des images extraites: 6
|
||||
2025-04-18 15:11:25 - root - INFO - 6 images intégrées extraites et ajoutées aux pièces jointes
|
||||
2025-04-18 15:11:26 - root - INFO - ------------------------------------------------------------
|
||||
2025-04-18 15:11:26 - root - INFO - Extraction terminée avec succès
|
||||
2025-04-18 15:11:26 - root - INFO - Ticket: T11143
|
||||
2025-04-18 15:11:26 - root - INFO - Répertoire: output/ticket_T11143/T11143_20250418_151124
|
||||
2025-04-18 15:11:26 - root - INFO - Messages traités: 7
|
||||
2025-04-18 15:11:26 - root - INFO - Pièces jointes: 7
|
||||
2025-04-18 15:11:26 - root - INFO - ------------------------------------------------------------
|
||||
2025-04-18 15:14:35 - root - INFO - Extraction du ticket T11143
|
||||
2025-04-18 15:14:35 - root - INFO - ------------------------------------------------------------
|
||||
2025-04-18 15:14:36 - root - INFO - Traitement de 1 pièces jointes pour le ticket 11122
|
||||
2025-04-18 15:14:36 - root - INFO - Pièce jointe téléchargée: image.png (1/1)
|
||||
2025-04-18 15:14:36 - root - INFO - ------------------------------------------------------------
|
||||
2025-04-18 15:14:36 - root - INFO - Extraction terminée avec succès
|
||||
2025-04-18 15:14:36 - root - INFO - Ticket: T11143
|
||||
2025-04-18 15:14:36 - root - INFO - Répertoire: output/ticket_T11143/T11143_20250418_151435
|
||||
2025-04-18 15:14:36 - root - INFO - Messages traités: 7
|
||||
2025-04-18 15:14:36 - root - INFO - Pièces jointes: 1
|
||||
2025-04-18 15:14:36 - root - INFO - ------------------------------------------------------------
|
||||
2025-04-18 15:17:35 - root - INFO - Extraction du ticket T11143
|
||||
2025-04-18 15:17:35 - root - INFO - ------------------------------------------------------------
|
||||
2025-04-18 15:17:36 - root - INFO - Données des messages chargées pour l'extraction des images intégrées
|
||||
2025-04-18 15:17:36 - root - INFO - Traitement de 1 pièces jointes pour le ticket 11122
|
||||
2025-04-18 15:17:36 - root - INFO - Pièce jointe téléchargée: image.png (1/1)
|
||||
2025-04-18 15:17:36 - root - INFO - Extraction des images intégrées aux messages...
|
||||
2025-04-18 15:17:36 - root - INFO - URLs d'images trouvées dans les messages: 10
|
||||
2025-04-18 15:17:36 - root - INFO - Image téléchargée depuis l'URL: https://img.mail.cbao.fr/im/2881244/543d7da1b54c29ff43ce5712d1a9aa4962ed21795c4e943fcb8cb84fd4d7465a.jpg?e=kEDXgN0xHfEb-981h_lc_yULm91O7bZKL_LYGfrT2K86Ta7cu921uClZUdgMhvotDWlcCzD3lJtBuoEhqI1Gywup4qaf3_WKJ6oubZu7p_5Stx-yi0SEGpWmdZd7tnRqk39JBwZTv6QvJDmP-3-8a_GVN6XIVj2mk65O7ASevFoYG54BN1Bzy0CebDYuMGOLCZGigDc_ZfReFYMsdxNdUnxNy9uoEFa9wO6djoxvs6pAQkJdPyaJMbf-vC-scsOjG4mbDhUUNKk
|
||||
2025-04-18 15:17:36 - root - INFO - Image téléchargée depuis l'URL: http://r.mail.cbao.fr/tr/op/5JbLgq7JMCd0cW4WUA-lgvTWXWdoLO1_ucWlr1Lq-Aahl3ciesDgM6O8PTgP7DJSRVCBx5lLZeGCOG9eZyn5F6PdDURFrtnzkWtHz8COpP16VAIdOWIpK8w_elOaV8Zi2U1ZjvCAMpCqfCYJYDADVxV2xRjq3plCjFMQ-FWOfmWoDIFWxksfoc2I5mhhnsrw
|
||||
2025-04-18 15:17:36 - root - ERROR - Erreur lors du téléchargement de l'image depuis /web_editor/font_to_img/61443/rgb(173,181,189)/13: Invalid URL '/web_editor/font_to_img/61443/rgb(173,181,189)/13': No scheme supplied. Perhaps you meant https:///web_editor/font_to_img/61443/rgb(173,181,189)/13?
|
||||
2025-04-18 15:17:36 - root - ERROR - Erreur lors du téléchargement de l'image depuis /web_editor/font_to_img/61446/rgb(173,181,189)/13: Invalid URL '/web_editor/font_to_img/61446/rgb(173,181,189)/13': No scheme supplied. Perhaps you meant https:///web_editor/font_to_img/61446/rgb(173,181,189)/13?
|
||||
2025-04-18 15:17:37 - root - INFO - Image téléchargée depuis l'URL: https://odoo.cbao.fr/web/image/145435?access_token=608ac9e7-3627-4a13-a8ec-06ff5046ebf3
|
||||
2025-04-18 15:17:37 - root - ERROR - Erreur lors du téléchargement de l'image depuis /web_editor/font_to_img/61534/rgb(144,144,144)/13: Invalid URL '/web_editor/font_to_img/61534/rgb(144,144,144)/13': No scheme supplied. Perhaps you meant https:///web_editor/font_to_img/61534/rgb(144,144,144)/13?
|
||||
2025-04-18 15:17:37 - root - INFO - Image téléchargée depuis l'URL: https://odoo.cbao.fr/web/image/145453?access_token=9c5d3a29-fce3-411f-8973-e3f33aa8f32c
|
||||
2025-04-18 15:17:37 - root - ERROR - Erreur lors du téléchargement de l'image depuis /web_editor/font_to_img/61618/rgb(173,181,189)/13: Invalid URL '/web_editor/font_to_img/61618/rgb(173,181,189)/13': No scheme supplied. Perhaps you meant https:///web_editor/font_to_img/61618/rgb(173,181,189)/13?
|
||||
2025-04-18 15:17:37 - root - INFO - Image téléchargée depuis l'URL: https://img.mail.cbao.fr/im/2881244/a20f7697fd5e1d1fca3296c6d01228220e0e112c46b4440cc938f74d10934e98.gif?e=J3oCbkWCHi7Jby6t0tMcS8mUioUDEMsJYthetssCVJI9F79WEhd03wXCmZ-MpVe_3kKAdx_UKcZh7LDpl4Os8alPD1hBRHXiL-2qkQEj4lUqUFcIVU3DjuHacMF2VQ1IaigOvBjMSkWrj63_l83dijq9mRqTXSs49fj4n3V7dQhw4xsQKlsroCMU2-_4smR8gNanwzu5M8xZrnbT6s3ze-l71gRqWBrO_iZDm8k3tZTQiEd0IHK_ydL2M7nO2Yqs1hKQsm0BdJW0RoUsbN51VgDXaWpY-XAoBAsEzhDdTyZcNdbwIaGtdhY9TXI72Egw6rdZ69UNJpQ4HuFZOJNYcFm6uCA0LxwFmx5n7nnYcYyY
|
||||
2025-04-18 15:17:37 - root - INFO - Image téléchargée depuis l'URL: https://img.mail.cbao.fr/im/2881244/5ad281b63492e31c9e66bf27518b816cdd3766cab9812bd4ff16b736e9e98265.jpg?e=8r2BeeTx41o7P48QGc8dTA9QZOB2GTlwPmvmUKM1mOEj7PIixgxi8THfMHUzkbxvWZ0IeDNk2GLdKrFDTFmFNUwsuze9m9iIGLsevTWvi9J0FKdCiHPM_N7oHl28BaOgXNM5hJnnQQiBDTuFH9yOdwtANlSU-In61mRTQcU059dPwIa6d7cW4mYPKAM316uk4wF5BzQTalI2490N3xfQO-NGNQq2w2JAiGOTUvWOI05ZCSyZ-qmoLbTFg6P9dUskVN6qx6F1PpKND8esvfmxiTdAIV1_tvg6owg8U_MCtUp8laoDr4Si8qIIDu02_ZtzEOxPW9rG0WCFcwx3
|
||||
2025-04-18 15:17:37 - root - INFO - Total des images extraites: 6
|
||||
2025-04-18 15:17:37 - root - INFO - 6 images intégrées extraites et ajoutées aux pièces jointes
|
||||
2025-04-18 15:17:37 - root - INFO - ------------------------------------------------------------
|
||||
2025-04-18 15:17:37 - root - INFO - Extraction terminée avec succès
|
||||
2025-04-18 15:17:37 - root - INFO - Ticket: T11143
|
||||
2025-04-18 15:17:37 - root - INFO - Répertoire: output/ticket_T11143/T11143_20250418_151735
|
||||
2025-04-18 15:17:37 - root - INFO - Messages traités: 7
|
||||
2025-04-18 15:17:37 - root - INFO - Pièces jointes: 7
|
||||
2025-04-18 15:17:37 - root - INFO - ------------------------------------------------------------
|
||||
|
||||
@ -1,14 +1,25 @@
|
||||
#!/usr/bin/env python3
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
"""
|
||||
Ce script était utilisé pour tester l'extraction d'images intégrées dans le HTML.
|
||||
Cette fonctionnalité a été désactivée suite à la suppression du module utils/image_extractor.
|
||||
Ce fichier est conservé à titre d'exemple mais n'est plus fonctionnel.
|
||||
"""
|
||||
|
||||
from odoo.attachment_manager import AttachmentManager
|
||||
from odoo.auth_manager import AuthManager
|
||||
import json
|
||||
import os
|
||||
|
||||
def main():
|
||||
print("La fonctionnalité d'extraction d'images intégrées dans le HTML a été désactivée.")
|
||||
print("Ce script est conservé à titre d'exemple mais n'est plus fonctionnel.")
|
||||
print("Si vous avez besoin de cette fonctionnalité, réinstallez le module utils/image_extractor.")
|
||||
|
||||
# Voici l'ancien code à titre d'exemple :
|
||||
"""
|
||||
# Initialiser le gestionnaire d'authentification avec des valeurs factices
|
||||
# puisque nous n'allons pas vraiment nous connecter à Odoo pour ce test
|
||||
auth = AuthManager(url='https://odoo.cbao.fr', db='dummy', username='dummy', api_key='dummy')
|
||||
|
||||
# Chemin vers le dossier du ticket
|
||||
@ -27,8 +38,7 @@ def main():
|
||||
print(f"Nombre d'images extraites: {len(extracted_images)}")
|
||||
for img in extracted_images:
|
||||
print(f"Image extraite: {img.get('name', 'Sans nom')} - {img.get('url', '')}")
|
||||
|
||||
print("Extraction terminée")
|
||||
"""
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
@ -1,104 +0,0 @@
|
||||
# Extracteur d'images HTML pour tickets Odoo
|
||||
|
||||
Ce module est conçu pour extraire les images intégrées dans les messages HTML des tickets Odoo. Il complète l'extracteur d'images standard existant pour assurer que toutes les images, y compris celles référencées uniquement dans le HTML des messages, sont correctement extraites.
|
||||
|
||||
## Problématique
|
||||
|
||||
Dans certains tickets Odoo, les images apparaissent dans le HTML des messages mais ne sont pas correctement détectées par l'extracteur d'images standard, en particulier lorsqu'elles sont référencées avec des balises `<img>` pointant vers des URLs comme `/web/image/ID?access_token=...`.
|
||||
|
||||
Ce module analyse le HTML des messages pour détecter ces références et les associer aux pièces jointes correspondantes, permettant ainsi d'extraire toutes les images associées à un ticket.
|
||||
|
||||
## Installation
|
||||
|
||||
Le module est conçu pour être intégré dans le projet existant et ne nécessite pas d'installation particulière. Il utilise cependant `BeautifulSoup` pour l'analyse HTML.
|
||||
|
||||
Si cette dépendance n'est pas déjà installée :
|
||||
|
||||
```bash
|
||||
pip install beautifulsoup4
|
||||
```
|
||||
|
||||
## Utilisation
|
||||
|
||||
### Utilisation simple
|
||||
|
||||
Pour extraire les images intégrées dans le HTML d'un ticket :
|
||||
|
||||
```python
|
||||
from utils.image_extractor import extract_images_from_ticket
|
||||
|
||||
# Chemin vers le répertoire du ticket
|
||||
ticket_dir = "output/ticket_T0241/T0241_20250409_141018"
|
||||
|
||||
# Extraire les images intégrées dans le HTML
|
||||
embedded_images = extract_images_from_ticket(ticket_dir)
|
||||
|
||||
# Afficher les chemins des images
|
||||
for img in embedded_images:
|
||||
print(f"Image trouvée: {img}")
|
||||
```
|
||||
|
||||
### Intégration complète
|
||||
|
||||
Pour intégrer l'extracteur HTML avec l'extracteur standard existant :
|
||||
|
||||
```python
|
||||
from utils.image_extractor.extract_all_images import enhance_ticket_data_with_images
|
||||
|
||||
# Données du ticket (contenant au minimum 'ticket_dir' et 'attachments')
|
||||
ticket_data = {
|
||||
"ticket_dir": "output/ticket_T0241/T0241_20250409_141018",
|
||||
"attachments": [...] # Liste des pièces jointes
|
||||
}
|
||||
|
||||
# Enrichir les données du ticket avec toutes les images
|
||||
enhanced_data = enhance_ticket_data_with_images(ticket_data)
|
||||
|
||||
# Accéder aux images combinées
|
||||
all_images = enhanced_data.get("images", [])
|
||||
standard_images = enhanced_data.get("standard_images", [])
|
||||
embedded_images = enhanced_data.get("embedded_images", [])
|
||||
```
|
||||
|
||||
### Script d'extraction complet
|
||||
|
||||
Un script utilitaire complet est également disponible :
|
||||
|
||||
```bash
|
||||
python -m utils.image_extractor.extract_ticket_images /chemin/vers/repertoire/ticket --verbose
|
||||
```
|
||||
|
||||
## Exemples
|
||||
|
||||
Le répertoire `examples` contient un exemple d'utilisation de l'extracteur sur le ticket T0241, qui présente des cas d'images intégrées dans le HTML.
|
||||
|
||||
```bash
|
||||
python -m utils.image_extractor.examples.extract_t0241_images
|
||||
```
|
||||
|
||||
## Structure du module
|
||||
|
||||
- `html_image_extractor.py` : Extracteur d'images HTML principal
|
||||
- `extract_all_images.py` : Module combinant l'extracteur HTML et l'extracteur standard
|
||||
- `extract_ticket_images.py` : Script utilitaire pour l'extraction d'images
|
||||
- `examples/` : Exemples d'utilisation
|
||||
|
||||
## Fonctionnement technique
|
||||
|
||||
1. L'extracteur charge les messages du ticket depuis `messages_raw.json`
|
||||
2. Il analyse le HTML des messages avec BeautifulSoup
|
||||
3. Il détecte les balises `<img>` avec des attributs `src` pointant vers `/web/image/ID`
|
||||
4. Il récupère l'ID de l'image et le lie aux pièces jointes disponibles dans `attachments_info.json`
|
||||
5. Il génère une liste des chemins locaux des images intégrées
|
||||
|
||||
## Avantages
|
||||
|
||||
- **Non intrusif** : Fonctionne en complément de l'extracteur existant, sans le modifier
|
||||
- **Robuste** : Gère différents formats de références d'images
|
||||
- **Configurable** : Peut être utilisé indépendamment ou intégré au flux de traitement existant
|
||||
- **Déduplication** : Évite les doublons entre les images standard et intégrées
|
||||
|
||||
## Limitations
|
||||
|
||||
- Nécessite que les pièces jointes référencées soient disponibles dans `attachments_info.json`
|
||||
- Dépend de BeautifulSoup pour l'analyse HTML
|
||||
@ -1 +0,0 @@
|
||||
from .html_image_extractor import HtmlImageExtractor, extract_images_from_ticket
|
||||
@ -1 +0,0 @@
|
||||
# Package d'exemples d'utilisation de l'extracteur d'images HTML
|
||||
@ -1,93 +0,0 @@
|
||||
#!/usr/bin/env python3
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
"""
|
||||
Script d'exemple pour extraire les images du ticket T0241.
|
||||
Cet exemple montre comment utiliser l'extracteur d'images HTML.
|
||||
"""
|
||||
|
||||
import os
|
||||
import sys
|
||||
import json
|
||||
|
||||
# Ajouter le répertoire parent au chemin de recherche
|
||||
parent_dir = os.path.abspath(os.path.join(os.path.dirname(__file__), '../../..'))
|
||||
sys.path.append(parent_dir)
|
||||
|
||||
from utils.image_extractor import extract_images_from_ticket
|
||||
from utils.image_extractor.extract_all_images import enhance_ticket_data_with_images
|
||||
|
||||
# Chemin vers le répertoire du ticket T0241
|
||||
ticket_dir = os.path.join(parent_dir, "output", "ticket_T0241", "T0241_20250409_141018")
|
||||
|
||||
def main():
|
||||
"""
|
||||
Fonction principale pour extraire les images du ticket T0241.
|
||||
"""
|
||||
if not os.path.exists(ticket_dir):
|
||||
print(f"Répertoire introuvable: {ticket_dir}")
|
||||
sys.exit(1)
|
||||
|
||||
print(f"Extraction des images pour le ticket: {os.path.basename(ticket_dir)}")
|
||||
|
||||
# 1. Utiliser directement l'extracteur d'images HTML
|
||||
print("\n1. Extraction des images intégrées dans le HTML:")
|
||||
embedded_images = extract_images_from_ticket(ticket_dir)
|
||||
print(f" Nombre d'images trouvées: {len(embedded_images)}")
|
||||
for img in embedded_images:
|
||||
print(f" - {os.path.basename(img)}")
|
||||
|
||||
# 2. Utiliser l'extracteur complet pour récupérer toutes les images
|
||||
print("\n2. Extraction de toutes les images (standard + intégrées):")
|
||||
|
||||
# Charger les données minimales du ticket
|
||||
ticket_data = {"ticket_dir": ticket_dir}
|
||||
|
||||
# Charger les pièces jointes si disponibles
|
||||
attachments_info_path = os.path.join(ticket_dir, "attachments_info.json")
|
||||
if os.path.exists(attachments_info_path):
|
||||
with open(attachments_info_path, 'r', encoding='utf-8') as f:
|
||||
ticket_data["attachments"] = json.load(f)
|
||||
|
||||
# Enrichir avec toutes les images
|
||||
enhanced_data = enhance_ticket_data_with_images(ticket_data)
|
||||
|
||||
# Afficher les statistiques
|
||||
stats = enhanced_data.get("images_stats", {})
|
||||
print(f" Total: {stats.get('total', 0)}")
|
||||
print(f" Standard: {stats.get('standard', 0)}")
|
||||
print(f" Intégrées: {stats.get('embedded', 0)}")
|
||||
|
||||
# Afficher les chemins des images
|
||||
print("\n Images standard:")
|
||||
for img in enhanced_data.get("standard_images", []):
|
||||
print(f" - {os.path.basename(img)}")
|
||||
|
||||
print("\n Images intégrées dans le HTML:")
|
||||
for img in enhanced_data.get("embedded_images", []):
|
||||
print(f" - {os.path.basename(img)}")
|
||||
|
||||
# 3. Sauvegarder les résultats
|
||||
output_file = os.path.join(ticket_dir, "all_images.json")
|
||||
result = {
|
||||
"images": enhanced_data.get("images", []),
|
||||
"standard_images": enhanced_data.get("standard_images", []),
|
||||
"embedded_images": enhanced_data.get("embedded_images", []),
|
||||
"stats": enhanced_data.get("images_stats", {})
|
||||
}
|
||||
|
||||
with open(output_file, 'w', encoding='utf-8') as f:
|
||||
json.dump(result, f, indent=2, ensure_ascii=False)
|
||||
|
||||
print(f"\nRésultats sauvegardés dans: {output_file}")
|
||||
|
||||
# Afficher un message pour intégrer cette fonctionnalité dans le flux de traitement
|
||||
print("\nPour intégrer cette fonctionnalité dans votre flux de traitement existant:")
|
||||
print("1. Importez l'extracteur d'images:")
|
||||
print(" from utils.image_extractor import extract_images_from_ticket")
|
||||
print("2. Utilisez-le pour compléter votre liste d'images:")
|
||||
print(" embedded_images = extract_images_from_ticket(ticket_dir)")
|
||||
print("3. Ajoutez ces images à votre liste d'images existante")
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
@ -1,169 +0,0 @@
|
||||
#!/usr/bin/env python3
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
"""
|
||||
Exemple d'intégration de l'extracteur d'images HTML dans un flux de traitement de ticket.
|
||||
Ce script montre comment utiliser l'extracteur d'images HTML comme une étape dans un processus
|
||||
d'analyse de tickets, par exemple dans un orchestrateur ou un analyseur de tickets.
|
||||
"""
|
||||
|
||||
import os
|
||||
import sys
|
||||
import json
|
||||
import logging
|
||||
from typing import Dict, Any, List
|
||||
|
||||
# Ajouter le répertoire parent au chemin de recherche
|
||||
parent_dir = os.path.abspath(os.path.join(os.path.dirname(__file__), '../../..'))
|
||||
sys.path.append(parent_dir)
|
||||
|
||||
# Importer l'extracteur d'images HTML
|
||||
from utils.image_extractor import extract_images_from_ticket
|
||||
from utils.image_extractor.extract_all_images import enhance_ticket_data_with_images
|
||||
|
||||
def setup_logging():
|
||||
"""Configure la journalisation."""
|
||||
logging.basicConfig(
|
||||
level=logging.INFO,
|
||||
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
|
||||
datefmt='%Y-%m-%d %H:%M:%S'
|
||||
)
|
||||
|
||||
def process_ticket(ticket_dir: str) -> Dict[str, Any]:
|
||||
"""
|
||||
Exemple de fonction qui traite un ticket complet.
|
||||
|
||||
Args:
|
||||
ticket_dir: Répertoire contenant les données du ticket
|
||||
|
||||
Returns:
|
||||
Données du ticket enrichies
|
||||
"""
|
||||
logging.info(f"Traitement du ticket dans: {ticket_dir}")
|
||||
|
||||
# 1. Charger les informations de base du ticket
|
||||
ticket_data = load_ticket_data(ticket_dir)
|
||||
|
||||
# 2. Extraire les images HTML
|
||||
logging.info("Extraction des images intégrées dans le HTML...")
|
||||
html_images = extract_images_from_ticket(ticket_dir)
|
||||
|
||||
# 3. Enrichir les données du ticket avec toutes les images
|
||||
ticket_data["ticket_dir"] = ticket_dir
|
||||
enhanced_data = enhance_ticket_data_with_images(ticket_data)
|
||||
|
||||
# 4. Ajouter des statistiques sur les images
|
||||
stats = enhanced_data.get("images_stats", {})
|
||||
logging.info(f"Images trouvées: {stats.get('total', 0)} total, " +
|
||||
f"{stats.get('standard', 0)} standard, " +
|
||||
f"{stats.get('embedded', 0)} intégrées")
|
||||
|
||||
# 5. Hypothétiquement, effectuer une analyse des images
|
||||
analyze_images(enhanced_data.get("images", []))
|
||||
|
||||
return enhanced_data
|
||||
|
||||
def load_ticket_data(ticket_dir: str) -> Dict[str, Any]:
|
||||
"""
|
||||
Charge les données du ticket depuis les fichiers JSON.
|
||||
|
||||
Args:
|
||||
ticket_dir: Répertoire contenant les données du ticket
|
||||
|
||||
Returns:
|
||||
Données du ticket chargées
|
||||
"""
|
||||
ticket_data = {}
|
||||
|
||||
# Charger les informations du ticket
|
||||
ticket_info_path = os.path.join(ticket_dir, "ticket_info.json")
|
||||
if os.path.exists(ticket_info_path):
|
||||
with open(ticket_info_path, 'r', encoding='utf-8') as f:
|
||||
ticket_data["ticket_info"] = json.load(f)
|
||||
|
||||
# Charger le résumé du ticket
|
||||
ticket_summary_path = os.path.join(ticket_dir, "ticket_summary.json")
|
||||
if os.path.exists(ticket_summary_path):
|
||||
with open(ticket_summary_path, 'r', encoding='utf-8') as f:
|
||||
ticket_data["ticket_summary"] = json.load(f)
|
||||
|
||||
# Charger les pièces jointes
|
||||
attachments_path = os.path.join(ticket_dir, "attachments_info.json")
|
||||
if os.path.exists(attachments_path):
|
||||
with open(attachments_path, 'r', encoding='utf-8') as f:
|
||||
ticket_data["attachments"] = json.load(f)
|
||||
|
||||
# Charger les messages
|
||||
messages_path = os.path.join(ticket_dir, "all_messages.json")
|
||||
if os.path.exists(messages_path):
|
||||
with open(messages_path, 'r', encoding='utf-8') as f:
|
||||
ticket_data["messages"] = json.load(f)
|
||||
|
||||
return ticket_data
|
||||
|
||||
def analyze_images(image_paths: List[str]):
|
||||
"""
|
||||
Exemple de fonction qui analyse les images d'un ticket.
|
||||
Cette fonction pourrait utiliser un modèle de vision ou une API externe.
|
||||
|
||||
Args:
|
||||
image_paths: Liste des chemins d'images à analyser
|
||||
"""
|
||||
logging.info(f"Analyse de {len(image_paths)} images...")
|
||||
|
||||
# Simuler une analyse d'images
|
||||
for i, img_path in enumerate(image_paths):
|
||||
if os.path.exists(img_path):
|
||||
logging.info(f" Analyse de l'image {i+1}: {os.path.basename(img_path)}")
|
||||
# TODO: Intégrer votre logique d'analyse d'image ici
|
||||
|
||||
def save_results(ticket_data: Dict[str, Any], output_file: str):
|
||||
"""
|
||||
Sauvegarde les résultats de l'analyse.
|
||||
|
||||
Args:
|
||||
ticket_data: Données du ticket à sauvegarder
|
||||
output_file: Chemin du fichier de sortie
|
||||
"""
|
||||
# Créer le répertoire de sortie si nécessaire
|
||||
output_dir = os.path.dirname(output_file)
|
||||
if output_dir and not os.path.exists(output_dir):
|
||||
os.makedirs(output_dir, exist_ok=True)
|
||||
|
||||
# Sauvegarder les résultats
|
||||
with open(output_file, 'w', encoding='utf-8') as f:
|
||||
json.dump(ticket_data, f, indent=2, ensure_ascii=False)
|
||||
|
||||
logging.info(f"Résultats sauvegardés dans: {output_file}")
|
||||
|
||||
def main():
|
||||
"""Fonction principale."""
|
||||
# Configurer la journalisation
|
||||
setup_logging()
|
||||
|
||||
# Récupérer le chemin du répertoire de ticket
|
||||
if len(sys.argv) > 1:
|
||||
ticket_dir = sys.argv[1]
|
||||
else:
|
||||
# Utiliser un répertoire de test par défaut
|
||||
ticket_dir = os.path.join(parent_dir, "output", "ticket_T0241", "T0241_20250409_141018")
|
||||
|
||||
# Vérifier que le répertoire existe
|
||||
if not os.path.exists(ticket_dir):
|
||||
logging.error(f"Répertoire introuvable: {ticket_dir}")
|
||||
sys.exit(1)
|
||||
|
||||
# Traiter le ticket
|
||||
ticket_data = process_ticket(ticket_dir)
|
||||
|
||||
# Sauvegarder les résultats
|
||||
output_file = os.path.join(ticket_dir, "ticket_analysis.json")
|
||||
save_results(ticket_data, output_file)
|
||||
|
||||
# Afficher un résumé
|
||||
ticket_code = ticket_data.get("ticket_summary", {}).get("code", os.path.basename(ticket_dir))
|
||||
print(f"\nAnalyse du ticket {ticket_code} terminée.")
|
||||
print(f"Résultats sauvegardés dans: {output_file}")
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
@ -1,162 +0,0 @@
|
||||
#!/usr/bin/env python3
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
"""
|
||||
Module combinant l'extracteur d'images standard avec l'extracteur d'images HTML.
|
||||
Permet de récupérer toutes les images liées à un ticket, qu'elles soient directement
|
||||
attachées ou référencées dans le HTML des messages.
|
||||
"""
|
||||
|
||||
import os
|
||||
import logging
|
||||
from typing import Dict, List, Any, Set
|
||||
from .html_image_extractor import extract_images_from_ticket
|
||||
|
||||
def enhance_ticket_data_with_images(ticket_data: Dict[str, Any]) -> Dict[str, Any]:
|
||||
"""
|
||||
Récupère toutes les images associées à un ticket, en combinant l'extraction standard
|
||||
et l'extraction des images intégrées dans le HTML.
|
||||
|
||||
Args:
|
||||
ticket_data: Données du ticket (avec la clé 'ticket_dir' contenant le chemin du répertoire)
|
||||
|
||||
Returns:
|
||||
Données du ticket enrichies avec les chemins des images
|
||||
"""
|
||||
result = ticket_data.copy()
|
||||
|
||||
# Vérifier que le répertoire du ticket est spécifié
|
||||
ticket_dir = ticket_data.get("ticket_dir")
|
||||
if not ticket_dir or not os.path.exists(ticket_dir):
|
||||
logging.error("Répertoire du ticket non spécifié ou introuvable")
|
||||
result["images"] = []
|
||||
result["standard_images"] = []
|
||||
result["embedded_images"] = []
|
||||
result["images_count"] = 0
|
||||
result["images_stats"] = {"total": 0, "standard": 0, "embedded": 0}
|
||||
return result
|
||||
|
||||
# 1. Récupérer les images standard depuis les pièces jointes
|
||||
standard_images = get_standard_images(ticket_data)
|
||||
|
||||
# 2. Récupérer les images intégrées dans le HTML
|
||||
try:
|
||||
embedded_images = extract_images_from_ticket(ticket_dir)
|
||||
except Exception as e:
|
||||
logging.error(f"Erreur lors de l'extraction des images HTML: {e}")
|
||||
embedded_images = []
|
||||
|
||||
# 3. Combiner les deux ensembles d'images et éliminer les doublons
|
||||
all_images = deduplicate_images(standard_images, embedded_images)
|
||||
|
||||
# 4. Enrichir les données du ticket
|
||||
result["images"] = all_images
|
||||
result["standard_images"] = standard_images
|
||||
result["embedded_images"] = embedded_images
|
||||
result["images_count"] = len(all_images)
|
||||
result["images_stats"] = {
|
||||
"total": len(all_images),
|
||||
"standard": len(standard_images),
|
||||
"embedded": len(embedded_images)
|
||||
}
|
||||
|
||||
return result
|
||||
|
||||
def get_standard_images(ticket_data: Dict[str, Any]) -> List[str]:
|
||||
"""
|
||||
Récupère les images standard depuis les pièces jointes du ticket.
|
||||
|
||||
Args:
|
||||
ticket_data: Données du ticket
|
||||
|
||||
Returns:
|
||||
Liste des chemins des images standard
|
||||
"""
|
||||
image_paths = []
|
||||
attachments = ticket_data.get("attachments", [])
|
||||
|
||||
if not attachments:
|
||||
return []
|
||||
|
||||
for attachment in attachments:
|
||||
# Vérifier si la pièce jointe est une image
|
||||
mimetype = attachment.get("mimetype", "").lower()
|
||||
name = attachment.get("name", "").lower()
|
||||
|
||||
# Vérifier si c'est une image par mimetype ou extension
|
||||
is_image = (
|
||||
mimetype.startswith("image/") or
|
||||
any(name.endswith(ext) for ext in ['.jpg', '.jpeg', '.png', '.gif', '.bmp', '.webp', '.svg'])
|
||||
)
|
||||
|
||||
if is_image:
|
||||
# Utiliser le chemin local s'il existe
|
||||
path = attachment.get("local_path")
|
||||
if path and os.path.exists(path):
|
||||
image_paths.append(path)
|
||||
|
||||
return image_paths
|
||||
|
||||
def deduplicate_images(standard_images: List[str], embedded_images: List[str]) -> List[str]:
|
||||
"""
|
||||
Combine deux listes d'images en éliminant les doublons.
|
||||
|
||||
Args:
|
||||
standard_images: Liste des chemins d'images standard
|
||||
embedded_images: Liste des chemins d'images intégrées
|
||||
|
||||
Returns:
|
||||
Liste combinée des chemins d'images sans doublons
|
||||
"""
|
||||
# Utiliser un ensemble pour éliminer les doublons
|
||||
unique_images = set(standard_images)
|
||||
|
||||
# Ajouter les images intégrées qui ne sont pas déjà dans les images standard
|
||||
for img in embedded_images:
|
||||
unique_images.add(img)
|
||||
|
||||
# Convertir en liste et vérifier que les chemins existent
|
||||
result = [img for img in unique_images if os.path.exists(img)]
|
||||
|
||||
return result
|
||||
|
||||
if __name__ == "__main__":
|
||||
# Test simple
|
||||
import sys
|
||||
|
||||
if len(sys.argv) > 1:
|
||||
ticket_dir = sys.argv[1]
|
||||
else:
|
||||
ticket_dir = "./output/ticket_T0241/T0241_20250409_141018"
|
||||
|
||||
if not os.path.exists(ticket_dir):
|
||||
print(f"Répertoire introuvable: {ticket_dir}")
|
||||
sys.exit(1)
|
||||
|
||||
# Charger les pièces jointes
|
||||
attachments_path = os.path.join(ticket_dir, "attachments_info.json")
|
||||
attachments = []
|
||||
|
||||
if os.path.exists(attachments_path):
|
||||
import json
|
||||
with open(attachments_path, 'r', encoding='utf-8') as f:
|
||||
attachments = json.load(f)
|
||||
|
||||
# Créer les données du ticket
|
||||
ticket_data = {
|
||||
"ticket_dir": ticket_dir,
|
||||
"attachments": attachments
|
||||
}
|
||||
|
||||
# Enrichir avec les images
|
||||
result = enhance_ticket_data_with_images(ticket_data)
|
||||
|
||||
# Afficher les résultats
|
||||
print(f"Images trouvées: {result['images_count']}")
|
||||
print(f" Images standard: {len(result['standard_images'])}")
|
||||
print(f" Images intégrées: {len(result['embedded_images'])}")
|
||||
|
||||
if result["images"]:
|
||||
print("\nListe des images:")
|
||||
for i, img in enumerate(result["images"]):
|
||||
print(f" {i+1}. {img}")
|
||||
@ -1,168 +0,0 @@
|
||||
#!/usr/bin/env python3
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
"""
|
||||
Script pour extraire toutes les images d'un ticket Odoo.
|
||||
Ce script combine l'extracteur d'images standard et l'extracteur d'images HTML.
|
||||
"""
|
||||
|
||||
import os
|
||||
import sys
|
||||
import json
|
||||
import argparse
|
||||
import logging
|
||||
from typing import Dict, List, Any, Optional
|
||||
|
||||
# Importer les extracteurs
|
||||
from .html_image_extractor import extract_images_from_ticket
|
||||
from .extract_all_images import enhance_ticket_data_with_images
|
||||
|
||||
def setup_logging(verbose: bool = False) -> None:
|
||||
"""
|
||||
Configure la journalisation.
|
||||
|
||||
Args:
|
||||
verbose: Mode verbeux pour plus de détails
|
||||
"""
|
||||
level = logging.DEBUG if verbose else logging.INFO
|
||||
logging.basicConfig(
|
||||
level=level,
|
||||
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
|
||||
datefmt='%Y-%m-%d %H:%M:%S'
|
||||
)
|
||||
|
||||
def extract_ticket_images(ticket_dir: str, output_file: Optional[str] = None, verbose: bool = False) -> Dict[str, Any]:
|
||||
"""
|
||||
Extrait toutes les images d'un ticket Odoo.
|
||||
|
||||
Args:
|
||||
ticket_dir: Répertoire du ticket
|
||||
output_file: Fichier de sortie pour les résultats (optionnel)
|
||||
verbose: Mode verbeux pour plus de détails
|
||||
|
||||
Returns:
|
||||
Dictionnaire avec les résultats de l'extraction
|
||||
"""
|
||||
setup_logging(verbose)
|
||||
|
||||
if not os.path.exists(ticket_dir):
|
||||
logging.error(f"Répertoire introuvable: {ticket_dir}")
|
||||
return {"status": "error", "message": "Répertoire introuvable"}
|
||||
|
||||
logging.info(f"Analyse des images pour le ticket dans: {ticket_dir}")
|
||||
|
||||
# Charger les données du ticket
|
||||
ticket_summary_path = os.path.join(ticket_dir, "ticket_summary.json")
|
||||
attachments_info_path = os.path.join(ticket_dir, "attachments_info.json")
|
||||
|
||||
ticket_data = {"ticket_dir": ticket_dir}
|
||||
|
||||
# Charger les données du ticket si disponibles
|
||||
if os.path.exists(ticket_summary_path):
|
||||
try:
|
||||
with open(ticket_summary_path, 'r', encoding='utf-8') as f:
|
||||
ticket_data["ticket_summary"] = json.load(f)
|
||||
logging.info("Données du ticket chargées")
|
||||
except Exception as e:
|
||||
logging.error(f"Erreur lors du chargement des données du ticket: {e}")
|
||||
|
||||
# Charger les pièces jointes si disponibles
|
||||
if os.path.exists(attachments_info_path):
|
||||
try:
|
||||
with open(attachments_info_path, 'r', encoding='utf-8') as f:
|
||||
ticket_data["attachments"] = json.load(f)
|
||||
logging.info(f"Pièces jointes chargées: {len(ticket_data['attachments'])}")
|
||||
except Exception as e:
|
||||
logging.error(f"Erreur lors du chargement des pièces jointes: {e}")
|
||||
|
||||
# Enrichir les données avec toutes les images
|
||||
try:
|
||||
enhanced_data = enhance_ticket_data_with_images(ticket_data)
|
||||
logging.info(f"Images identifiées: {enhanced_data.get('images_count', 0)}")
|
||||
|
||||
# Préparer les résultats
|
||||
result = {
|
||||
"status": "success",
|
||||
"ticket_dir": ticket_dir,
|
||||
"images": enhanced_data.get("images", []),
|
||||
"standard_images": enhanced_data.get("standard_images", []),
|
||||
"embedded_images": enhanced_data.get("embedded_images", []),
|
||||
"stats": enhanced_data.get("images_stats", {})
|
||||
}
|
||||
|
||||
# Ajouter les informations du ticket si disponibles
|
||||
if "ticket_summary" in enhanced_data:
|
||||
ticket_summary = enhanced_data["ticket_summary"]
|
||||
result["ticket_code"] = ticket_summary.get("code", "")
|
||||
result["ticket_name"] = ticket_summary.get("name", "")
|
||||
|
||||
# Sauvegarder les résultats si un fichier de sortie est spécifié
|
||||
if output_file:
|
||||
output_dir = os.path.dirname(output_file)
|
||||
if output_dir and not os.path.exists(output_dir):
|
||||
os.makedirs(output_dir, exist_ok=True)
|
||||
|
||||
with open(output_file, 'w', encoding='utf-8') as f:
|
||||
json.dump(result, f, indent=2, ensure_ascii=False)
|
||||
logging.info(f"Résultats sauvegardés dans: {output_file}")
|
||||
else:
|
||||
# Utiliser un fichier de sortie par défaut dans le répertoire du ticket
|
||||
default_output = os.path.join(ticket_dir, "all_images.json")
|
||||
with open(default_output, 'w', encoding='utf-8') as f:
|
||||
json.dump(result, f, indent=2, ensure_ascii=False)
|
||||
logging.info(f"Résultats sauvegardés dans: {default_output}")
|
||||
|
||||
return result
|
||||
|
||||
except Exception as e:
|
||||
logging.exception(f"Erreur lors de l'extraction des images: {e}")
|
||||
return {"status": "error", "message": str(e)}
|
||||
|
||||
def parse_arguments():
|
||||
"""
|
||||
Parse les arguments de la ligne de commande.
|
||||
|
||||
Returns:
|
||||
Arguments parsés
|
||||
"""
|
||||
parser = argparse.ArgumentParser(description="Extrait toutes les images d'un ticket Odoo.")
|
||||
parser.add_argument("ticket_dir", help="Répertoire du ticket")
|
||||
parser.add_argument("--output", "-o", help="Fichier de sortie pour les résultats")
|
||||
parser.add_argument("--verbose", "-v", action="store_true", help="Mode verbeux pour plus de détails")
|
||||
return parser.parse_args()
|
||||
|
||||
def main():
|
||||
"""
|
||||
Point d'entrée principal.
|
||||
"""
|
||||
args = parse_arguments()
|
||||
|
||||
result = extract_ticket_images(
|
||||
ticket_dir=args.ticket_dir,
|
||||
output_file=args.output,
|
||||
verbose=args.verbose
|
||||
)
|
||||
|
||||
# Afficher un résumé des résultats
|
||||
if result["status"] == "success":
|
||||
stats = result.get("stats", {})
|
||||
print("\nStatistiques des images:")
|
||||
print(f" Total: {stats.get('total', 0)}")
|
||||
print(f" Standard: {stats.get('standard', 0)}")
|
||||
print(f" Intégrées: {stats.get('embedded', 0)}")
|
||||
|
||||
# Afficher les chemins des images
|
||||
if args.verbose:
|
||||
print("\nImages standard:")
|
||||
for img in result.get("standard_images", []):
|
||||
print(f" {img}")
|
||||
|
||||
print("\nImages intégrées dans le HTML:")
|
||||
for img in result.get("embedded_images", []):
|
||||
print(f" {img}")
|
||||
else:
|
||||
print(f"Erreur: {result.get('message', 'Erreur inconnue')}")
|
||||
sys.exit(1)
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
@ -1,449 +0,0 @@
|
||||
#!/usr/bin/env python3
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
"""
|
||||
Module pour extraire les images intégrées dans les messages HTML d'Odoo.
|
||||
Complémentaire à l'extracteur d'images actuel, il détecte spécifiquement les images
|
||||
référencées dans le HTML avec des balises <img> et les associe aux pièces jointes.
|
||||
"""
|
||||
|
||||
import os
|
||||
import re
|
||||
import logging
|
||||
import json
|
||||
from typing import Dict, List, Any, Optional, Set, Tuple
|
||||
from bs4 import BeautifulSoup
|
||||
|
||||
class HtmlImageExtractor:
|
||||
"""
|
||||
Extracteur d'images intégrées dans les messages HTML d'Odoo.
|
||||
"""
|
||||
|
||||
def __init__(self, ticket_dir: str):
|
||||
"""
|
||||
Initialise l'extracteur d'images HTML.
|
||||
|
||||
Args:
|
||||
ticket_dir: Répertoire du ticket contenant les messages et pièces jointes
|
||||
"""
|
||||
self.ticket_dir = ticket_dir
|
||||
self.messages_file = os.path.join(ticket_dir, "messages_raw.json")
|
||||
self.attachments_file = os.path.join(ticket_dir, "attachments_info.json")
|
||||
self.output_file = os.path.join(ticket_dir, "embedded_images.json")
|
||||
|
||||
# Cache pour les données
|
||||
self._messages = None
|
||||
self._attachments = None
|
||||
|
||||
def _load_messages(self) -> List[Dict[str, Any]]:
|
||||
"""
|
||||
Charge les messages du ticket.
|
||||
|
||||
Returns:
|
||||
Liste des messages
|
||||
"""
|
||||
if self._messages is not None:
|
||||
return self._messages
|
||||
|
||||
# Essayer différents fichiers potentiels contenant les messages
|
||||
possible_message_files = [
|
||||
self.messages_file, # messages_raw.json
|
||||
os.path.join(self.ticket_dir, "messages.json"),
|
||||
os.path.join(self.ticket_dir, "all_messages.json")
|
||||
]
|
||||
|
||||
for msg_file in possible_message_files:
|
||||
if os.path.exists(msg_file):
|
||||
try:
|
||||
with open(msg_file, 'r', encoding='utf-8') as f:
|
||||
data = json.load(f)
|
||||
|
||||
# Gérer différents formats de fichiers de messages
|
||||
if isinstance(data, dict):
|
||||
if "messages" in data:
|
||||
self._messages = data["messages"]
|
||||
return self._messages
|
||||
# Si pas de clé messages mais d'autres clés, essayer de trouver les messages
|
||||
for key, value in data.items():
|
||||
if isinstance(value, list) and len(value) > 0:
|
||||
# Vérifier si ça ressemble à des messages (ont une clé body ou content)
|
||||
if isinstance(value[0], dict) and any(k in value[0] for k in ["body", "content"]):
|
||||
self._messages = value
|
||||
return self._messages
|
||||
|
||||
# Si c'est directement une liste, supposer que ce sont des messages
|
||||
elif isinstance(data, list):
|
||||
self._messages = data
|
||||
return self._messages
|
||||
|
||||
except Exception as e:
|
||||
logging.error(f"Erreur lors du chargement du fichier {msg_file}: {e}")
|
||||
|
||||
# Si on arrive ici, aucun fichier valide n'a été trouvé
|
||||
logging.error(f"Aucun fichier de messages valide trouvé dans: {self.ticket_dir}")
|
||||
return []
|
||||
|
||||
def _load_attachments(self) -> Dict[int, Dict[str, Any]]:
|
||||
"""
|
||||
Charge les pièces jointes du ticket.
|
||||
|
||||
Returns:
|
||||
Dictionnaire des pièces jointes indexées par ID
|
||||
"""
|
||||
if self._attachments is not None:
|
||||
return self._attachments
|
||||
|
||||
# Essayer différents fichiers potentiels de pièces jointes
|
||||
possible_attachment_files = [
|
||||
self.attachments_file, # attachments_info.json
|
||||
os.path.join(self.ticket_dir, "attachments.json")
|
||||
]
|
||||
|
||||
for att_file in possible_attachment_files:
|
||||
if os.path.exists(att_file):
|
||||
try:
|
||||
with open(att_file, 'r', encoding='utf-8') as f:
|
||||
attachments = json.load(f)
|
||||
|
||||
if not isinstance(attachments, list):
|
||||
# Si ce n'est pas une liste mais un dict, essayer de trouver une liste
|
||||
for key, value in attachments.items():
|
||||
if isinstance(value, list) and len(value) > 0:
|
||||
attachments = value
|
||||
break
|
||||
|
||||
if not isinstance(attachments, list):
|
||||
continue
|
||||
|
||||
# Indexer par ID pour un accès rapide
|
||||
self._attachments = {}
|
||||
for att in attachments:
|
||||
if "id" in att:
|
||||
self._attachments[att["id"]] = att
|
||||
elif "attachment_id" in att:
|
||||
self._attachments[att["attachment_id"]] = att
|
||||
|
||||
if self._attachments:
|
||||
return self._attachments
|
||||
except Exception as e:
|
||||
logging.error(f"Erreur lors du chargement des pièces jointes depuis {att_file}: {e}")
|
||||
|
||||
# Si on arrive ici, aucun fichier valide n'a été trouvé
|
||||
logging.error(f"Aucun fichier de pièces jointes valide trouvé dans: {self.ticket_dir}")
|
||||
return {}
|
||||
|
||||
def _get_tag_attribute(self, tag: Any, attr_name: str, default: str = "") -> str:
|
||||
"""
|
||||
Récupère un attribut d'une balise HTML de manière sécurisée.
|
||||
|
||||
Args:
|
||||
tag: Balise HTML
|
||||
attr_name: Nom de l'attribut à récupérer
|
||||
default: Valeur par défaut si l'attribut n'existe pas
|
||||
|
||||
Returns:
|
||||
Valeur de l'attribut
|
||||
"""
|
||||
# Vérifier que c'est bien une balise et qu'elle a la méthode get
|
||||
if not hasattr(tag, 'get'):
|
||||
return default
|
||||
|
||||
# Récupérer l'attribut si présent
|
||||
try:
|
||||
value = tag.get(attr_name)
|
||||
return str(value) if value is not None else default
|
||||
except (AttributeError, KeyError, TypeError):
|
||||
return default
|
||||
|
||||
def extract_image_references(self) -> Dict[str, Any]:
|
||||
"""
|
||||
Extrait les références aux images dans le HTML des messages.
|
||||
|
||||
Returns:
|
||||
Dictionnaire contenant les références d'images trouvées
|
||||
"""
|
||||
messages = self._load_messages()
|
||||
attachments_by_id = self._load_attachments()
|
||||
|
||||
if not messages:
|
||||
logging.error("Aucun message trouvé pour l'extraction d'images")
|
||||
return {"status": "error", "message": "Aucun message trouvé", "references": []}
|
||||
|
||||
# Stocker les références trouvées
|
||||
image_references = []
|
||||
|
||||
# Ensemble pour dédupliquer
|
||||
processed_ids = set()
|
||||
|
||||
for message in messages:
|
||||
# Déterminer quel champ contient le contenu HTML
|
||||
message_body = None
|
||||
message_id = None
|
||||
|
||||
# Différentes possibilités de noms pour le contenu HTML et l'ID
|
||||
for body_key in ["body", "content", "html_content", "message"]:
|
||||
if body_key in message and message[body_key]:
|
||||
message_body = message[body_key]
|
||||
break
|
||||
|
||||
for id_key in ["id", "message_id", "uid"]:
|
||||
if id_key in message:
|
||||
message_id = message[id_key]
|
||||
break
|
||||
|
||||
if not message_body or not message_id:
|
||||
continue
|
||||
|
||||
# Méthode 1: Extraction depuis les balises <img> dans le HTML
|
||||
try:
|
||||
# Analyser le HTML du message
|
||||
soup = BeautifulSoup(message_body, "html.parser")
|
||||
|
||||
# Trouver toutes les balises <img>
|
||||
img_tags = soup.find_all("img")
|
||||
|
||||
for img in img_tags:
|
||||
# Utiliser la méthode sécurisée pour récupérer les attributs
|
||||
src = self._get_tag_attribute(img, "src")
|
||||
|
||||
# Ignorer les images vides ou data URLs
|
||||
if not src or src.startswith("data:"):
|
||||
continue
|
||||
|
||||
# Différents patterns de référence d'images
|
||||
image_id = None
|
||||
|
||||
# Pattern 1: /web/image/ID?access_token=...
|
||||
match = re.search(r"/web/image/(\d+)", src)
|
||||
if match:
|
||||
image_id = int(match.group(1))
|
||||
|
||||
# Pattern 2: /web/content/ID?...
|
||||
if not image_id:
|
||||
match = re.search(r"/web/content/(\d+)", src)
|
||||
if match:
|
||||
image_id = int(match.group(1))
|
||||
|
||||
# Pattern 3: /web/static/ID?...
|
||||
if not image_id:
|
||||
match = re.search(r"/web/static/(\d+)", src)
|
||||
if match:
|
||||
image_id = int(match.group(1))
|
||||
|
||||
# Pattern 4: /web/binary/image?id=ID&...
|
||||
if not image_id:
|
||||
match = re.search(r"[?&]id=(\d+)", src)
|
||||
if match:
|
||||
image_id = int(match.group(1))
|
||||
|
||||
if image_id:
|
||||
self._ajouter_reference_image(image_id, message_id, attachments_by_id, img, processed_ids, image_references)
|
||||
|
||||
except Exception as e:
|
||||
logging.error(f"Erreur lors de l'analyse des balises <img> dans le message {message_id}: {e}")
|
||||
|
||||
# Méthode 2: Extraction depuis les références textuelles à la fin du message
|
||||
# Format: "- Nom_image.ext (image/type) [ID: 12345]"
|
||||
try:
|
||||
# Chercher des références d'images dans le texte du message
|
||||
# Pattern des références: "- Nom_fichier.ext (type/mime) [ID: 12345]"
|
||||
img_ref_pattern = r"- ([^\(\)]+) \(([^\(\)]*)\) \[ID: (\d+)\]"
|
||||
for match in re.finditer(img_ref_pattern, message_body):
|
||||
try:
|
||||
nom_fichier = match.group(1).strip()
|
||||
mimetype = match.group(2).strip()
|
||||
image_id = int(match.group(3))
|
||||
|
||||
if image_id in processed_ids:
|
||||
continue
|
||||
|
||||
processed_ids.add(image_id)
|
||||
|
||||
# Vérifier si cette image est dans nos pièces jointes
|
||||
if image_id in attachments_by_id:
|
||||
attachment = attachments_by_id[image_id]
|
||||
|
||||
# Récupérer le chemin local de l'image
|
||||
local_path = attachment.get("local_path")
|
||||
|
||||
# Vérifier que le fichier existe réellement
|
||||
if local_path and not os.path.exists(local_path):
|
||||
# Essayer de chercher dans d'autres endroits potentiels du répertoire
|
||||
for root, dirs, files in os.walk(self.ticket_dir):
|
||||
for file in files:
|
||||
if os.path.basename(local_path) == file:
|
||||
local_path = os.path.join(root, file)
|
||||
break
|
||||
if os.path.exists(local_path):
|
||||
break
|
||||
|
||||
image_ref = {
|
||||
"image_id": image_id,
|
||||
"message_id": message_id,
|
||||
"attachment_id": attachment.get("id", attachment.get("attachment_id", 0)),
|
||||
"name": nom_fichier, # Utiliser le nom trouvé dans le texte
|
||||
"mimetype": mimetype, # Utiliser le type MIME trouvé dans le texte
|
||||
"file_size": attachment.get("file_size", 0),
|
||||
"local_path": local_path,
|
||||
"source": "text_reference"
|
||||
}
|
||||
|
||||
image_references.append(image_ref)
|
||||
logging.info(f"Image référencée trouvée dans le texte: ID {image_id} dans message {message_id}")
|
||||
except Exception as e:
|
||||
logging.error(f"Erreur lors du traitement de la référence d'image textuelle: {e}")
|
||||
|
||||
except Exception as e:
|
||||
logging.error(f"Erreur lors de l'analyse des références textuelles dans le message {message_id}: {e}")
|
||||
|
||||
# Sauvegarder les références trouvées
|
||||
result = {
|
||||
"status": "success" if image_references else "warning",
|
||||
"message": f"Trouvé {len(image_references)} références d'images intégrées",
|
||||
"references": image_references
|
||||
}
|
||||
|
||||
try:
|
||||
with open(self.output_file, 'w', encoding='utf-8') as f:
|
||||
json.dump(result, f, indent=2, ensure_ascii=False)
|
||||
logging.info(f"Références d'images sauvegardées dans: {self.output_file}")
|
||||
except Exception as e:
|
||||
logging.error(f"Erreur lors de la sauvegarde des références d'images: {e}")
|
||||
|
||||
return result
|
||||
|
||||
def _ajouter_reference_image(self, image_id: int, message_id: str, attachments_by_id: Dict[int, Dict[str, Any]],
|
||||
img: Any, processed_ids: Set[int], image_references: List[Dict[str, Any]]) -> None:
|
||||
"""
|
||||
Ajoute une référence d'image à la liste des références
|
||||
|
||||
Args:
|
||||
image_id: ID de l'image
|
||||
message_id: ID du message
|
||||
attachments_by_id: Dictionnaire des pièces jointes indexées par ID
|
||||
img: Balise HTML de l'image
|
||||
processed_ids: Ensemble des IDs déjà traités
|
||||
image_references: Liste des références d'images à enrichir
|
||||
"""
|
||||
# Éviter les duplications
|
||||
if image_id in processed_ids:
|
||||
return
|
||||
|
||||
processed_ids.add(image_id)
|
||||
|
||||
# Vérifier si cette image est dans nos pièces jointes
|
||||
if image_id in attachments_by_id:
|
||||
attachment = attachments_by_id[image_id]
|
||||
|
||||
# Récupérer les attributs de manière sécurisée
|
||||
width = self._get_tag_attribute(img, "width")
|
||||
height = self._get_tag_attribute(img, "height")
|
||||
alt = self._get_tag_attribute(img, "alt")
|
||||
|
||||
# Récupérer le chemin local de l'image
|
||||
local_path = attachment.get("local_path")
|
||||
|
||||
# Vérifier que le fichier existe réellement
|
||||
if local_path and not os.path.exists(local_path):
|
||||
# Essayer de chercher dans d'autres endroits potentiels du répertoire
|
||||
for root, dirs, files in os.walk(self.ticket_dir):
|
||||
for file in files:
|
||||
if os.path.basename(local_path) == file:
|
||||
local_path = os.path.join(root, file)
|
||||
break
|
||||
if os.path.exists(local_path):
|
||||
break
|
||||
|
||||
image_ref = {
|
||||
"image_id": image_id,
|
||||
"message_id": message_id,
|
||||
"attachment_id": attachment.get("id", attachment.get("attachment_id", 0)),
|
||||
"name": attachment.get("name", ""),
|
||||
"mimetype": attachment.get("mimetype", ""),
|
||||
"file_size": attachment.get("file_size", 0),
|
||||
"local_path": local_path,
|
||||
"img_width": width,
|
||||
"img_height": height,
|
||||
"img_alt": alt,
|
||||
"source": "html_img_tag"
|
||||
}
|
||||
|
||||
image_references.append(image_ref)
|
||||
logging.info(f"Image intégrée trouvée: ID {image_id} dans message {message_id}")
|
||||
|
||||
def get_image_paths(self) -> List[str]:
|
||||
"""
|
||||
Récupère les chemins des images référencées.
|
||||
|
||||
Returns:
|
||||
Liste des chemins locaux des images référencées
|
||||
"""
|
||||
try:
|
||||
# Tenter d'extraire les images
|
||||
data = self.extract_image_references()
|
||||
|
||||
# Récupérer les chemins locaux des images
|
||||
paths = []
|
||||
for ref in data.get("references", []):
|
||||
path = ref.get("local_path")
|
||||
if path and os.path.exists(path):
|
||||
paths.append(path)
|
||||
|
||||
if not paths:
|
||||
logging.warning("Aucune image intégrée trouvée ou les chemins sont invalides")
|
||||
|
||||
return paths
|
||||
|
||||
except Exception as e:
|
||||
logging.error(f"Erreur lors de la récupération des chemins d'images: {e}")
|
||||
return []
|
||||
|
||||
def extract_images_from_ticket(ticket_dir: str) -> List[str]:
|
||||
"""
|
||||
Fonction utilitaire pour extraire les images intégrées dans les messages HTML d'un ticket.
|
||||
|
||||
Args:
|
||||
ticket_dir: Répertoire du ticket contenant les messages et pièces jointes
|
||||
|
||||
Returns:
|
||||
Liste des chemins locaux des images référencées
|
||||
"""
|
||||
extractor = HtmlImageExtractor(ticket_dir)
|
||||
return extractor.get_image_paths()
|
||||
|
||||
if __name__ == "__main__":
|
||||
# Test avec un répertoire de ticket spécifique
|
||||
import sys
|
||||
|
||||
if len(sys.argv) > 1:
|
||||
ticket_dir = sys.argv[1]
|
||||
else:
|
||||
# Utiliser un répertoire de test par défaut
|
||||
ticket_dir = "./output/ticket_T0241/T0241_20250409_141018"
|
||||
|
||||
if not os.path.exists(ticket_dir):
|
||||
print(f"Répertoire introuvable: {ticket_dir}")
|
||||
sys.exit(1)
|
||||
|
||||
print(f"Extraction des images intégrées dans le HTML pour le ticket: {os.path.basename(ticket_dir)}")
|
||||
|
||||
extractor = HtmlImageExtractor(ticket_dir)
|
||||
result = extractor.extract_image_references()
|
||||
|
||||
print(f"Statut: {result['status']}")
|
||||
print(f"Message: {result['message']}")
|
||||
print(f"Nombre de références trouvées: {len(result['references'])}")
|
||||
|
||||
for i, ref in enumerate(result["references"]):
|
||||
print(f"\nImage {i+1}:")
|
||||
print(f" ID: {ref['image_id']}")
|
||||
print(f" Nom: {ref['name']}")
|
||||
print(f" Type: {ref['mimetype']}")
|
||||
print(f" Taille: {ref['file_size']} octets")
|
||||
print(f" Chemin local: {ref['local_path']}")
|
||||
|
||||
# Récupérer les chemins des images
|
||||
paths = extractor.get_image_paths()
|
||||
print(f"\nChemins des images ({len(paths)}):")
|
||||
for path in paths:
|
||||
print(f" {path}")
|
||||